こんにちは。
はるかです。
新しいサーチコンソールが正式版としてリリースされました。
従いまして、従来のサーチコンソールの機能は全て移行されます。
移行の段階で、使われない機能の削除と改善が同時に行われていますので、よく確認して戸惑う事のないようにしてください。
ヘルプには、旧機能のと新機能の対比や改訂された用語また、移行されていない機能などが整理されています。
旧機能で出来たのに?と思う場合、まず確認してください。
本記事では、新しいサーチコンソールに絞って、インデックスカバレッジレポートの解析の仕方をわかりやすく説明したいと思います。
なおGoogleは、サーチコンソールの利用者が満足できるように常に改善する姿勢です。
機能について「あれ?」とか「こうだったらいいのに」という気づきがあったら、ぜひ左下の「フィードバックを送信」からGoogleに情報を送信してください。
それは、送信者/Googleだけではなく、私たちウェブマスター全体の利益につながります。(〃ω〃)
インデックスカバレッジレポートは、「エラー」→「有効(警告あり)」→「有効」→「除外」というように、構造がツリー形式になっています。
各項目応じて、発生するエラー内容や対処しなければならい問題を分かりやすく解説したいと思います。
なお私は、Googleのインデックスはコントロールすべきと主張しています。
インデックスは多い方が良いとか、ウェブマスターは何もせずGoogleに任せるとか、こういう運営方針はさまざまな問題を発生させる可能性があります。
せっかく作ったサイトなのですから、自分の想定しているキーワードで検索して、正しく想定したページが検索結果に表示される様に構成して欲しいです。
想定したキーワードでページが表示されるようちょっとしたノウハウも提示してみたいと思います。

では、順番に見ていきましょう。
レポートの確認の仕方と優先順位
インデックスカバレッジレポートを確認するには、サーチコンソールにログインして、左(モバイルでは左上のアコーデオンメニュー)から「カバレッジ」を選択します。するとデフォルトで以下のような画面が表示されます。
インデックスカバレッジレポート
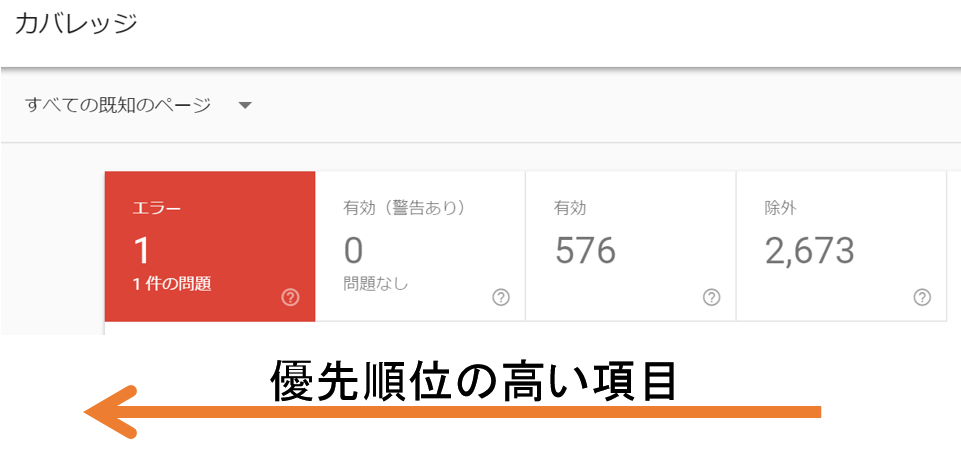
それぞれ以下の順番で表示されています。
・エラー
・有効(警告有り)
・有効
・除外
この項目は、左に行くほど対処しなければならない問題の優先順位が高くなっています。
ただし、優先順位はあくまで目安です。
管理するサイトにとって何が最重要なのか?
ウェブマスターが適切な判断を下せるように解説していきます。
インデックカバレッジポートの画面には、さらに便利な機能が追加されてます。
左上にあるプルダウンで次の項目が選択できるようになっているのです。
問題切り分けのためのフィルター
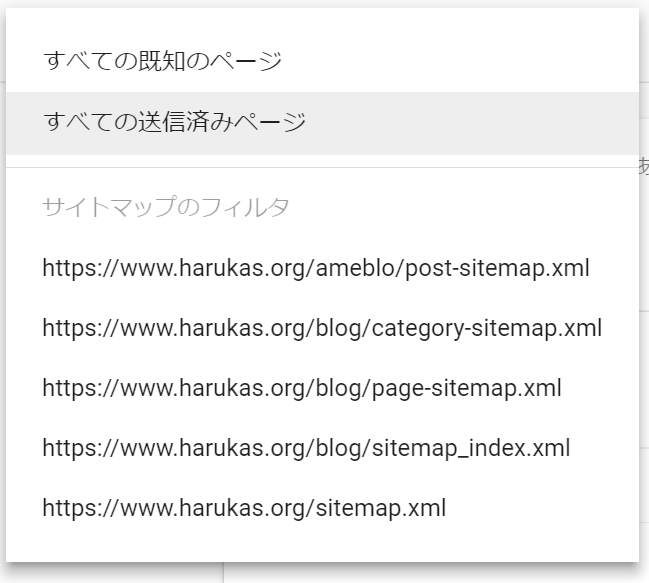
・全ての既知ページ
・全ての送信済みページ
この二つの違いは、サイトマップで等でウェブマスターが意識してインデックスの登録要求を行ったページなのか、Googleがリンクなどをたどり、サイトをクロールして勝手に検出してきたページなのかの違いです。
大規模サイトでは、サイトマップを小分けする事で問題の特定をスムーズに行うことが出来ます。
数百ページクラスのブログでも、年次にサイトマップを変えたりすることにより解析時間の短縮がはかれます。
この機能は、Googleが自動検知したエラーか、自分で送信したページがエラーなのかをフィルターする機能です。
サイトマップの小分けは問題を特定する時とても役に立ちますので、ぜひ利用してみてください。
では、インデックスカバレッジに表示される「有効」以外の3つの項目を詳細に解説します。
エラーがレポートされた場合の確認項目と対処
エラーは、デフォルトで表示されており、赤背景になっています。背景をクリックすることによって、選択を解除できます。
エラー

エラーの項目が検出されている場合は、サイトマップで送信したページなのか、それ以外なのかを確認します。
デフォルトでは「すべての既知のページ」が選択されていますので、ここを「すべての送信済みページ」に切り替えてエラーが消えるかどうか確認します。
それで消えたら、Googleが勝手に検出したURLでエラーが発生したという事が分かります。
仮に「すべての送信済みのページ」でエラーが表示されているのは、とてもおかしな状況なので速やかに対処してください。
エラーで検出した項目は、インデックスに登録されていません。
それなのにサイトマップで送信しているという事は、ウェブマスターはページを登録したいがGoogleには拒否されているという事です。
次項以降でエラーの種類によって、どのような対策をしなければならないかを解説しています。
サイトマップで余計なものを送信していてた…というオチもありますので、そういった確認も出来ます。
さてSEOの基本事項をご存じですか?
それは、サイトをくまなくGooglebotにクロール(サイトを網の目の様に巡回すること)してもらう事です。
Googleはページ内のコンテンツをさまざまなアルゴリズムで、検索キーワードの回答になり得るかを調べています。
従ってクロールが出来ないとか、クロールに対してエラーを返す等は、SEOの基本が出来ていない事になります。
まず、クロールが適切に行われている事を確認しましょう。
クロールされたものがインデックスされ、ランキングされて、はじめて検索結果に表示されます。
クロール→インデキシング→ランキング
インデックスに関する問題に対処するには、インデキシングの前工程であるクロールを適切に処理する必要があるのです。
Googlebotは得たいの知れないものではありません。
2019年5月Googlebotは、evergeen化しました。
これにより、最新版で安定稼働(stable)されたChromeのバージョンの約10日後にGooglebotとして活動します。
つまりChromeの最新レンダリングエンジンを備えたブラウザで、サイトを巡回してくると思って良いです。
Googlebotがサイトを巡回途中でエラーになるようなら、その原因がエラーとしてレポートされます。
クロールについて詳細に知りたい場合、私がまとめたものがあります。
クロールバジェットをコントロールする事の重要性について
是非、時間のあるときに読んでみてください。
エラーが検出されたときは、まずレポートされたURLを、ブラウザ表示してください。
ブラウザの閲覧でエラーになれば、Googlebotが巡回してもエラーになります。
エラーの解除に全力を集中します。
その時に表示されるエラーコードは、エラーの原因を探るのに役立ちます。
エラーコードで4xxや5xxが返却されるようであれば、サーバーが返却したコードに応じたエラーが記録されます。
5xxエラーの発生原因と対策方法
5xxは、サーバー設定を間違えた場合に発生する事が多く、Apacheであれば主にhttpd.confの外部ファイルである.htaccessの記述ミスで簡単に発生します。また、WordPressを使っている場合、functions.phpなど重要なファイルを変更したり、修正をミスしたりしてもすぐに発生する事があります。
サイトの構成を変えたりhtaccessを触ったり、プラグインをインストールしたりした場合も、発生することがあります。
原因追及は時間掛かるでしょうから、今までちゃんと動いていたなら、前の状態に戻すのが手っ取り早いです。
SEOに限らずSEO以外にも言えることですが問題が起きたら元に戻すは鉄則です。
何かの大きな修正を行う場合、必ず元に戻せるようにします。
バックアップなしでサイトを修正するとこういうときに戻せなくなるので、必ずバックアップを取りましょう。
(自動で良いです。cornの使えるサーバーなら、テーマを夜中に別のディレクトリに自動コピーするなどで充分)
5xxのエラーは、その他サーバーのパフォーマンスを超えた場合のトランザクションでも発生します。
SNS等で取り上げられてバズに耐える事ができないと503や500などになります。
5xxエラーの対処は大きく分けて二つです。
①再現性(確実に発生するか)
→確実に発生する場合は、問題となっている原因を追及し除去する
該当のURLで確実に5xxエラーになる場合、処理/設定の誤りが殆どあり対処も容易です。
原因を追及し解除したこともブラウザ等で確認できると思います。
ブラウザで確認するには、F12(Win)を押して表示される開発者モードの「ネットワーク」で確認できます。
サーバーが何のエラーコードを返却しているか分からない場合は、SEOチェキ(ヘッダー情報チェック)などの外部サイトで確認する事も可能です。
②発生頻度(どの程度の頻度で発生するか)
→たまにしか発生しない場合は、頻度の確認とログなどから原因を追求し対処の有無を判断する
頻度は、あるプラグインが実行されたときとか、あるページだけとか、そういうのを細かく調べます。
サーバーのエラーログやアクセスログは、解析に役に立つと思いますので、それを見る事ができるホスティング会社の場合、ログなどから状況を推察します。
全く原因が推測できずエラーがないのに低頻度で500などが発生する場合は、ホスティングのプランなどを変更したり会社を変更したりする必要があるかもしれません。(恐らくサーバーリソースの問題)
レンタルサーバーは、仮想システムやマルチアカウント対応のアプリケーションで稼働しており、複数のアカウントを同一物理サーバーで動作させています。
そのため、あるアカウントがCPU能力を一時的に占有したり、HDD(SSD)のバスを占有したりすると、パフォーマンス問題が発生する可能性があります。
一つの物理サーバーに同居する他のアカウントの問題は、原因追及するのがとても難しくホスティング業者に依頼するのが得策です。
どうしても原因が分からない場合は、調査内容をレポートにして、ホスティング業者に提示を行い、頼っても良いと思います。
次に日本からブラウザでサイトを見ると全く問題はないのに、5xxエラーが記録されたりする事があります。
そういった現象が発生する場合は、次の手順で確認します。
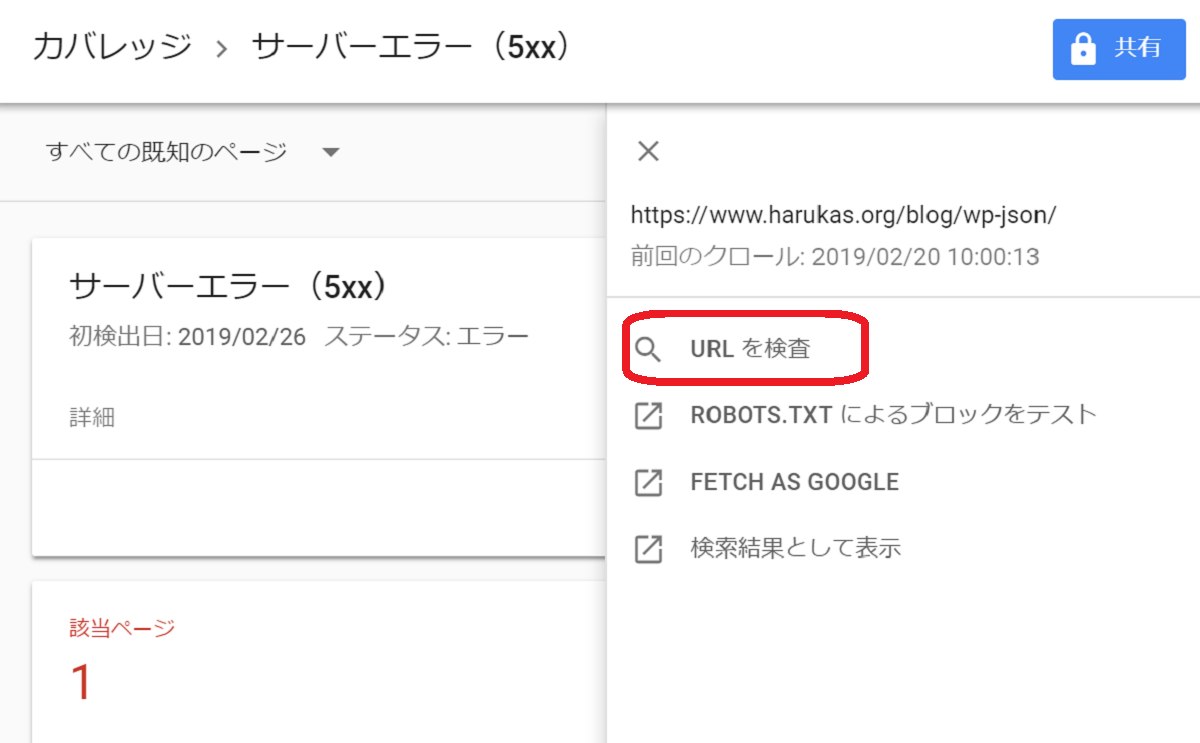
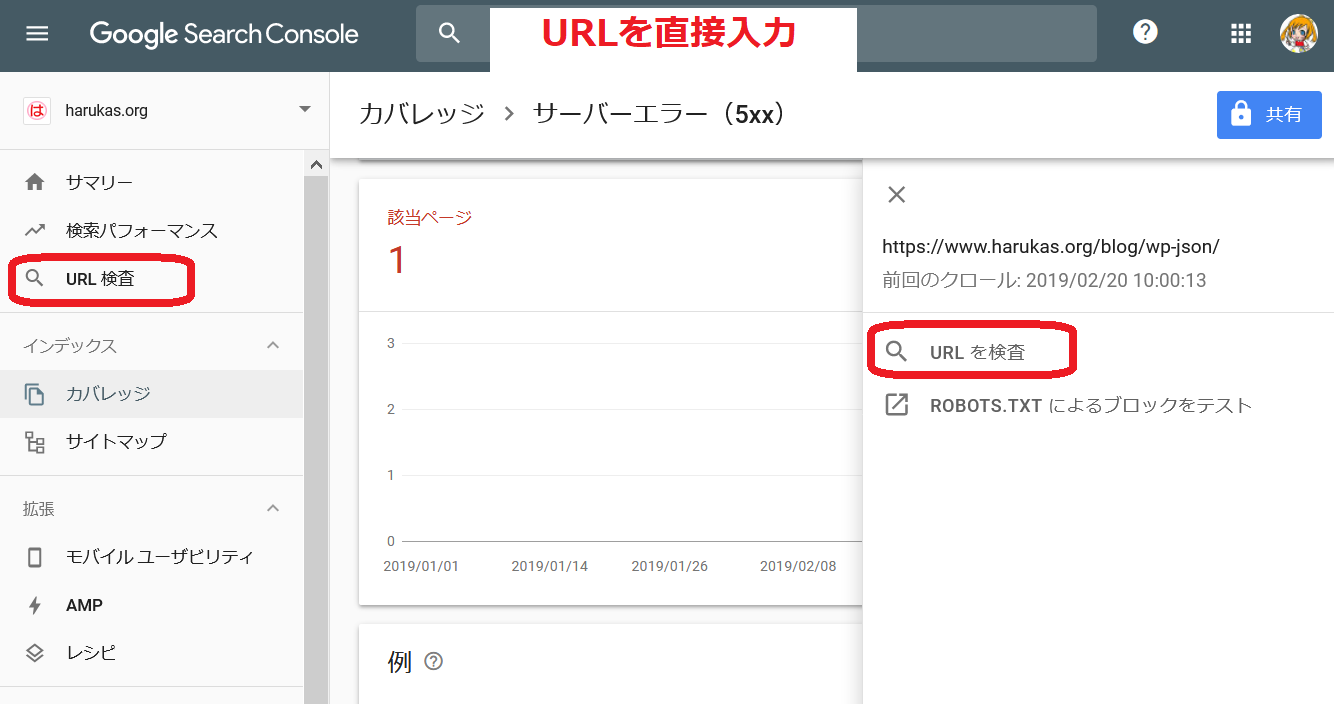
サーチコンソールのURL検査ツールを使います。
エラーで検出されているURLをクリックするとメニューがでてきますので、それで「URLの検査」を選択します。
5xxエラーをURL検査
次に「公開URLをテスト」押すことによって、Googlebotをサイトに呼び込み、その時のレンダリング状態やサーバーが返却するレスポンスを確認する事ができます。
公開URLをテストは、ライブテストなので現在のWebサイトの状況を知ることができます。
ライブテストでGooglebotに返却している確実なレスポンスを確認したい場合は、URL検査ツールを使ってください。
URL検査ツールでサーバーレスポンスを確認する
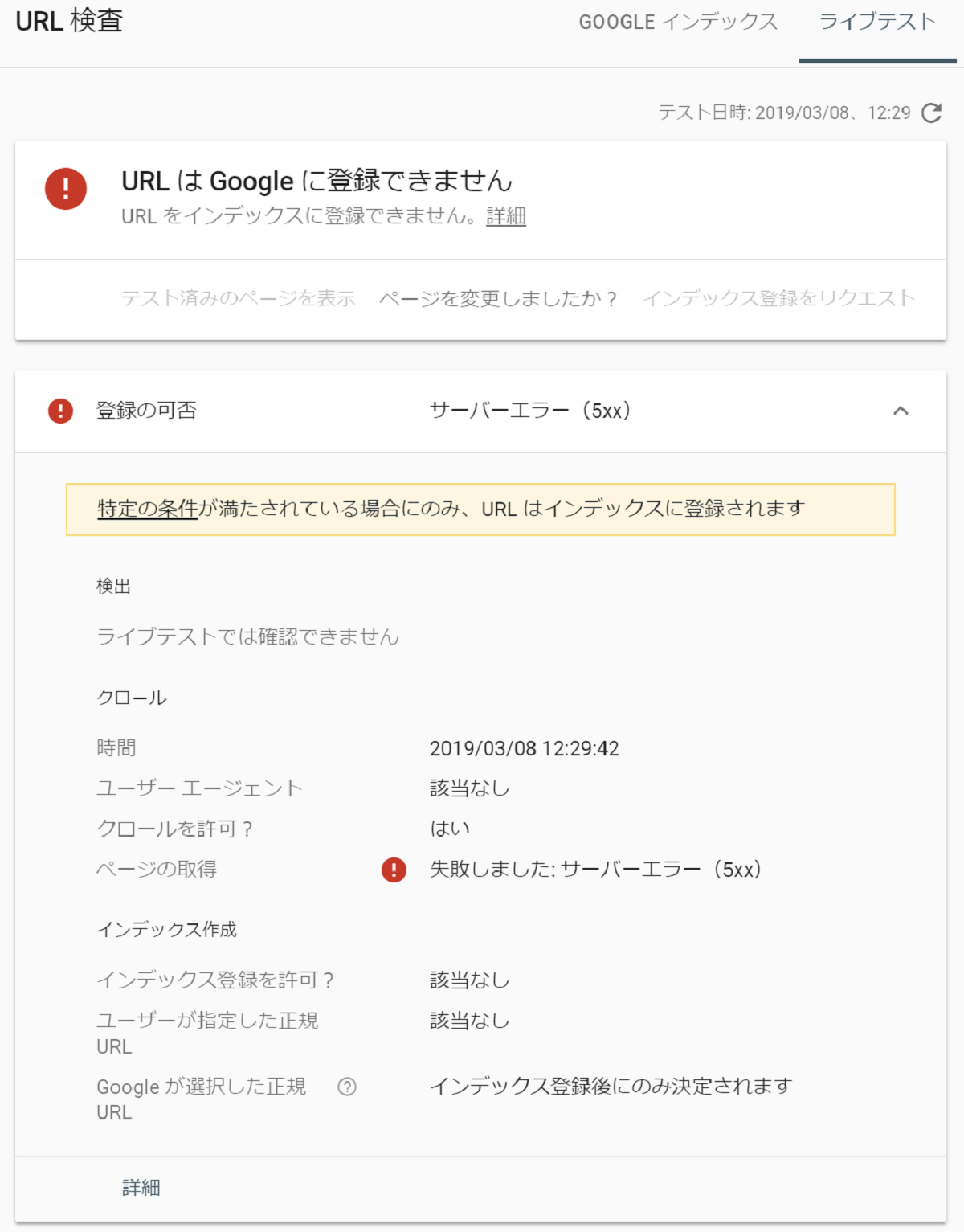
私の5xxエラーの発生原因は、WordPressでREST-APIを抑止しているために発生しています。
ちゃんと制御すれば401にできるのでしょうけど、運用に支障がないため、無視しています。
一番左の「エラー」で5xxが必ず発生するものでも、このように無視できるものがあります。
ウェブマスターは、このような判断をすべてのエラー項目で実施します。
なお、URL検査ツールは、さまざまなトラブルシューティングに使用できるので、ぜひともサーチコンソールにサイトを登録して、すぐに使えるように環境を整備しておいてくださいね。
URL検査ツール以外で、Googlebotの振る舞いを見たい場合があると思います。
実は、それに最適なツールが幾つかあります。
・モバイルフレンドリーテスト
・ページスピードインサイト
・リッチリザルトテスト
です。
これらのツールはめちゃくちゃ優秀で、クロールに関する問題をトラブルシューティングするためにサイトの管理者でなくても利用できるという優れものです。
もちろん、各目的を遂行するためのツールですから、自分のサイトはURL検査ツールを使いましょう。
これらのツールでは、「robots.txt」により当該URLがブロックされているか否かの確認も可能です。
さらにGooglebotを送出するアメリカにあるサーバーでステータスを確認する事ができますので、初心者に多い「海外からのアクセスをブロックする」という設定をONしてしまった場合のトラブルを見つけることもできます。
モバイルフレンドリーテストは、画面は小さいですがレンダリング結果も出力しますので、簡易なレンダリング確認も行えます。
モバイルフレンドリーテスト
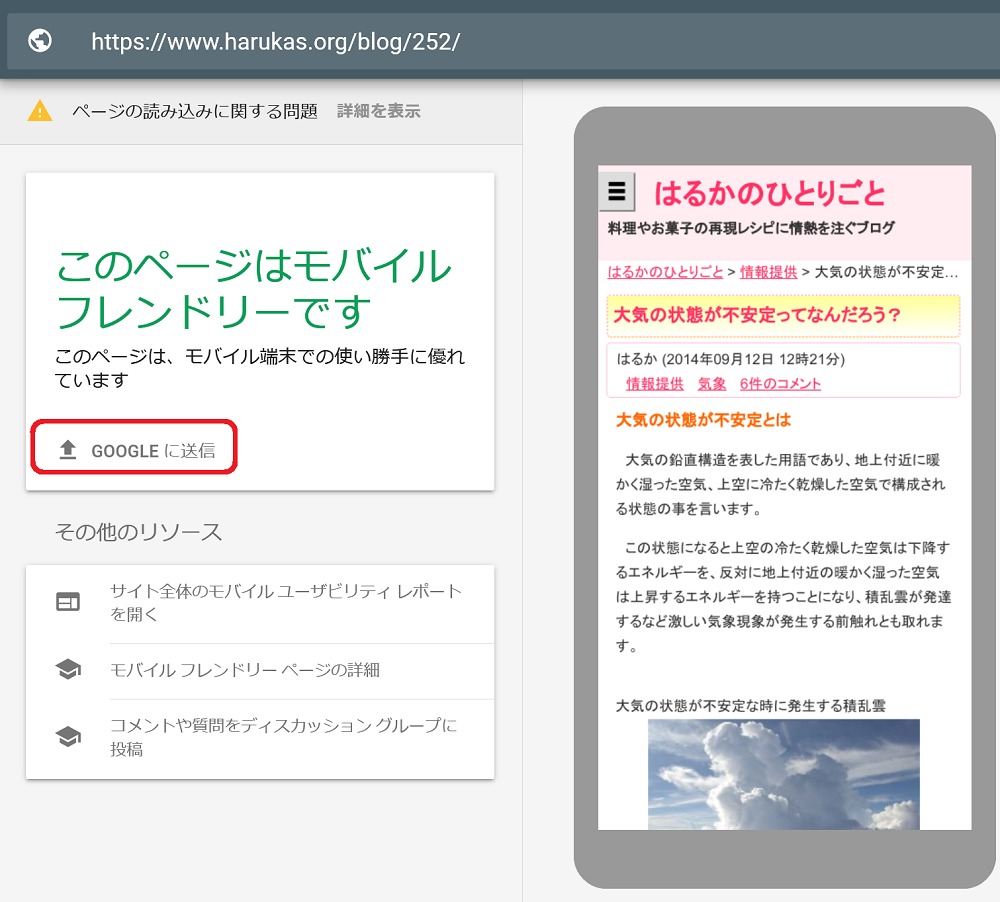
このように、モバイルフレンドリーテストやPageSpeedInsightは、簡易なインデックス状態を確認するツールとして使うことが出来ます。
リッチリザルトを確認するリッチリザルトテストもある程度インデックスを確認する事が可能です。
こちらはあくまで、マークアップした構造化データの確からしさを検証し、リッチリザルトのシミュレーションを行うツールです。
リッチリザルトテスト画面
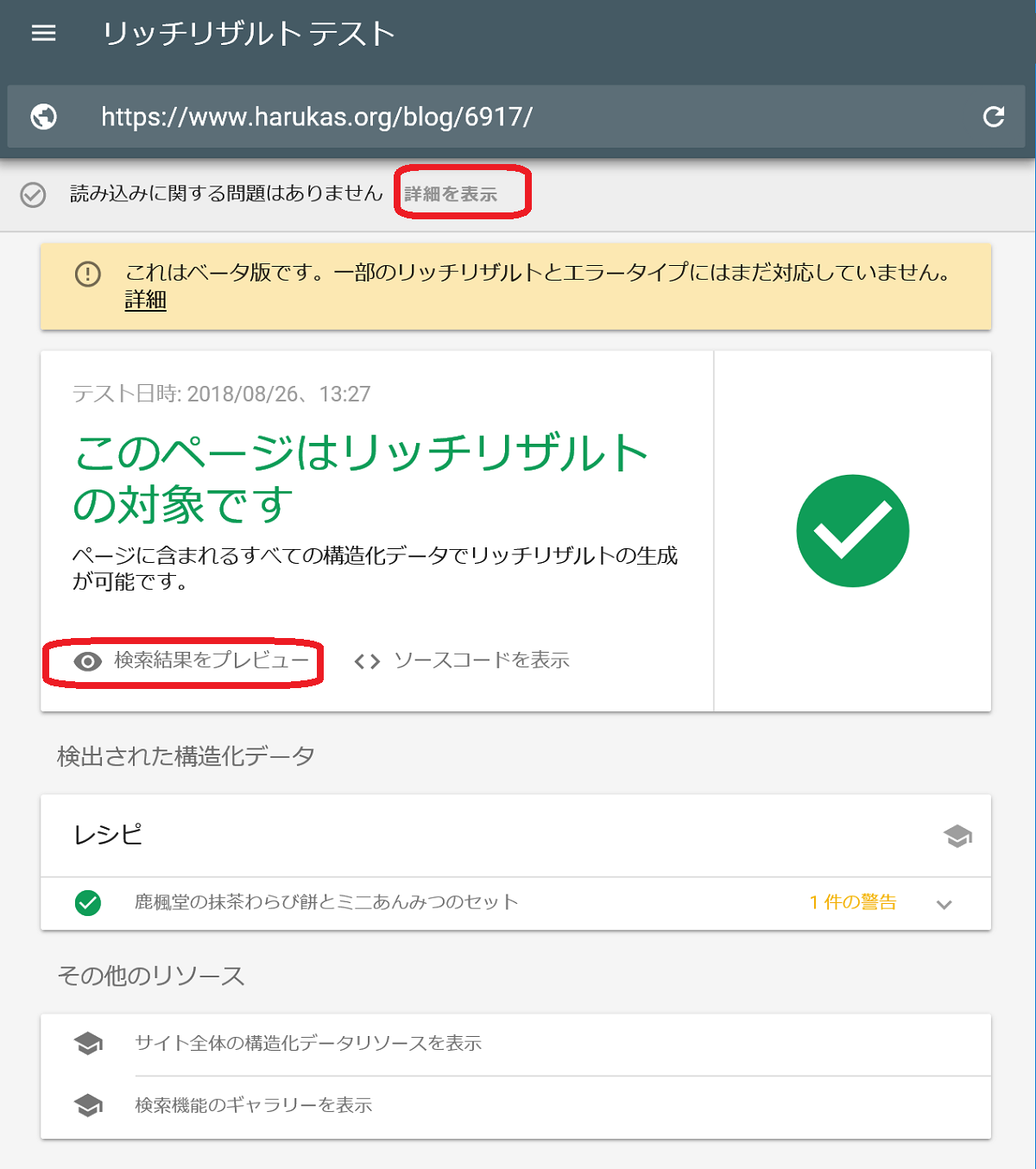
表示の通りβ版なので、まだまだ機能が追加されるかもしれません。
また画面デザインを見て分かると思いますが、これは新しいサーチコンソールと同じような新機能です。
よく見ると驚くべき機能が搭載されています。
例えば読み込みに関する問題の詳細をクリックします。
するとGooglebotがサイトインデックスしたとき、PCのGooglebotがインデックスしたのかモバイルのGooglebotがインデックスしたのか確認する事ができ、簡易なJavaScriptコンソールでWordPressが吐き出すJQueryのメッセージを表示したり、スタックトレースを確認する事が出来ます。
リッチリザルトを実装するために、構造化データをJSでマークアップする場合もあるかと思います。
そのときGooglebotに正しく構造化データが理解されているのか、ソースを見て確認する事が可能です。
検索結果のプレビューは画像付きでリッチリザルトを表示する事ができます。
ソースの表示類は、承知の通りGooglebotがインデックスした時点のものです。
(最新の情報を知りたい場合は、URL検査の公開URLをテストの機能でライブテストしてください)
Googleのインデックスに送信するベストプラクティス
2020年1月現在、Googleへインデックスを送信できる機能は、次の3つです。1.URL検査ツールでページの更新を通知
2.サイトマップの送信
3.インデックスAPIの使用
です。
Fetch as Googleは、2019年3月に、機能提供を終了しサーチコンソールに移行されました。
1.URL検査ツールでページの更新を通知
サーチコンソールのURL検査を使用する方法です。
インデックスしてほしいURLに対して、URL検査を行うと「インデックス登録をリクエスト」というボタンが現れます。
ボタン一つで素早くインデックスしてくれるので、便利に使いましょう。
URL検査ツールでインデックス登録をリクエスト
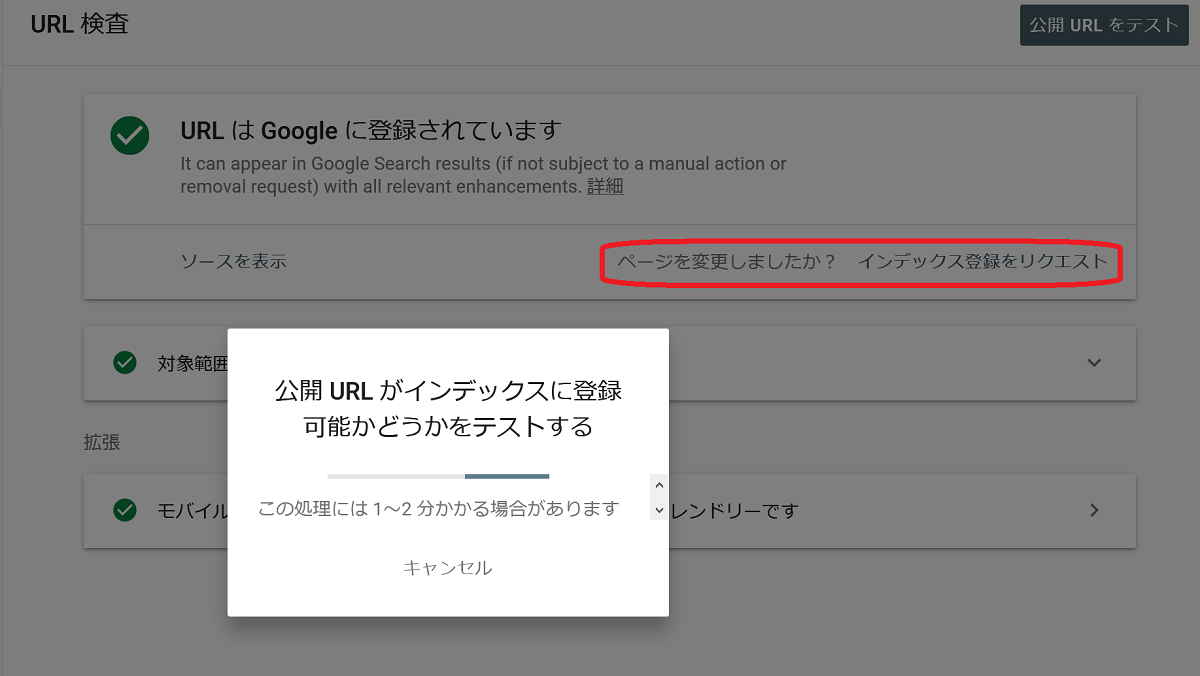
ページを変更しましたか?の後ろにある「インデックス登録をリクエスト」ボタンを押すことにより、インデックスに送信する事が可能です。
サーチコンソールからインデックスに関するエラーが通知され、サイトを修正を行った場合「修正の確認を行う」というボタンでもインデックス登録を即す事ができます。
修正確認のボタンを押した後、もう一度ページを変更しましたか?で送信する必要はありません。
2.サイトマップの送信
Googleに継続的にインデックスを正しく送信するベストプラクティスは、サイトマップを送信することです。
正しいサイトマップ構成と矛盾のないサイトマップを送信する事で、サイトの更新状態を素早くGoogleに伝える事ができます。
サイトマップを構成する上で、矛盾がないというも重要です。
canonical元のurlをサイトマップに記載したり、noindexのurlを記載したりするものではありません。
またrobots.txtでブロックしているURLを指定したり404のURLを指定するとクロールエラーになるでしょう。
サイトマップの送信には、いくつかの手順があります。
最初に、サイトマップのアップロード場所の指定です。
サイトマップファイルをアップロードしたら、そのURLを検索エンジンに伝えなければなりません。
一般的にrobots.txtに記述する事が知られています。
Googleでは、アップロードしたサイトマップファイルのURLを直接指定する事が出来ます。
ですが、ここでは様々な検索エンジンに対応するため、robots.txtに記述することをお勧めします。
方法は、ドメインやサブドメインのトップにあるrobots.txtにサイトマップのURLを記載するだけです。
ただし、robots.txt内にコメントなどマルチバイト文字を使っている場合は、必ずUTF-8にしてください。
意味がわからない場合は、コメントであっても日本語などの全角文字を一切使わないでください。
(マルチバイトを使用すると、自動的にテキスト形式がSHIFT-JISなどgooglebotで読み取れない形式になります)
robots.txtには、サイトマップを記載したい場合は「Sitemap:URL」を記述します。
robot.txtにサイトマップURLを記述する
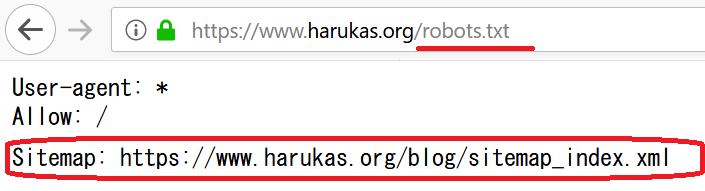
robots.txtの編集に自信が無い場合は、無理に使用する必要はありません。
robotx.txtは、検索エンジンにとって重要なファイルなので5xxなどを返却すると、インデックスが全て削除される可能性もあります。
編集やアクセス権の設定には充分注意してください。
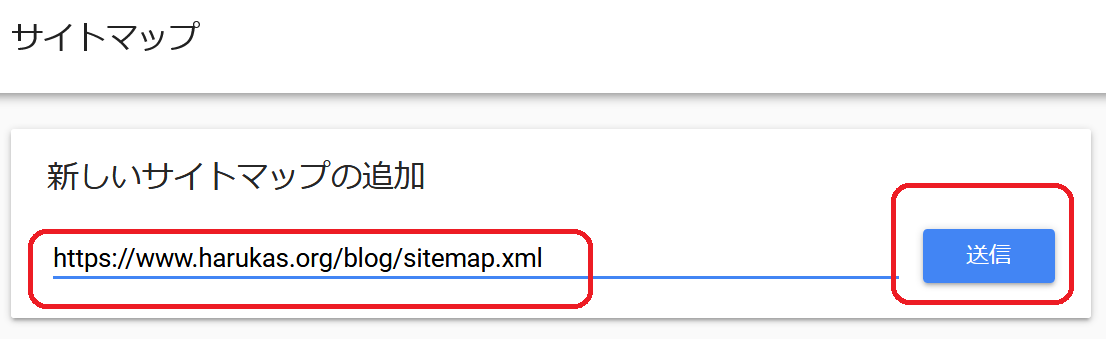
robots.txtを使用せずサイトマップのアップロード場所を指定するには、サーチコンソールの機能でサイトマップを追加します。
サイトマップ→新しいサイトマップの追加
より、アップロードしたサイトマップのURLを追加して送信します。
(プロパティ配下の下位ディレクトリ)
サーチコンソールでサイトマップの追加
サイトマップをいくら追記したところで、すぐにクロールされる訳ではありません。
サイトマップ自体がクロールされないことには、Googleは、どのページが更新されたのか理解できません。
また、lastmodを記載しないtxtファイルの場合は、追加されたり削除されたURLを確認しますが、やはりサイトマップファイルである.txtファイルがクロールされないと判断は出来ません。
サイトマップをGoogleにクロールしてもらうには、サイトマップのURLをPingで送信します。
サイトマップPingでGoogleに送信

Googleの場合
https://www.google.com/webmasters/tools/ping?sitemap=Bingの場合
https://www.bing.com/webmaster/ping.aspx?siteMap=WordPressを使用している場合、著名なSEOプラグイン、例えばYoastSEOは、記事を編集したら自動的にsitemap Pingを送信してくれます。
GoogleのインデックスにURLを送信する手段は限られていますので、サイトマップを正しく使ってください。
Googleが対応しているサイトマップ形式はこれだけあります。
作りやすい/扱いやすいものを選択してください。
ヘルプの通り、テキストなら1行1URLをテキストで記述して、.txtというファイルを作りアップロードするだけです。
あとは、サーチコンソールでそのテキストファイルのURLを記述して送信すればOKです。
CMSを使用していない環境では、こういった形で作られても良いと思います。
3.インデックスAPIの使用
現在、仕事検索/動画配信/動画しか対応しておりませんが、APIを利用することにより、素早くURLの追加/更新/削除をGoogleに伝える事が出来ます。
APIを利用してインデックスに送信しますので、速度は最速になります。
GCPを使用して制御しますので、APIを扱う基本的な知識やサーバーが必要です。
(アクセストークンの生成や利用など)
Indexing API クイックスタート
https://developers.google.com/search/apis/indexing-api/v3/quickstart?hl=ja
404/ソフト404の原因と対策方法
404や410は「コンテンツが見つかりません」という意味です。この数字は、あくまでGooglebotに対して、サーバーが返却するコードです。
このコードとレンダリング結果は、実は一致していない事があるのです。
何が言いたいかよく分かりませんね。こう言う意味です。
①サーバーは200を返しコンテンツも正常表示
②サーバーは200を返すがコンテンツは「見つかりません」
③サーバーは404を返すがコンテンツは正常表示
④サーバーは404を返しコンテンツは「見つかりません」
こう箇条書きにすれば①と④がコードと画面が合っているというのが分かります。
世の中全て①と④だけなら問題ないのですが、残念なことに②と③を出す場合があるのですね・・・。
②サーバーは200を返すがコンテンツは「見つかりません」
これは、ソフト404というコードになる事が多いです。
たとえば、Webサイトにサイト検索フォームを備えている場合があり、そこにサイトに存在しない情報を入れると、通常「見つかりません」と表示します。
このとき、意図的に404になる様に設定していないと200で「見つかりません」を表示してしまいます。
ちゃんとレスポンスを確認して、見つからない時は404、見つかったときは200になる様にします。
これは余談ですが、私は検索画面はインデックスすべきではないと啓蒙しています。
リンク記述先の内容は、ぜひとも守って欲しいです。
ソフト404を意図的に発生させるのは難しいです。
Googleは内部処理でもう一つの大きな原因もソフト404とします。
その原因とは同じURLでコンテンツが全く違う場合です。
同じURLでコンテンツが違うといってもピンときません。
例えば、次の様な状態を指します。
ソフト404になり得る操作
(1)中古ドメインを購入した
(2)サイトを削除/修正した
(3)全く違う記事に301リダイレクト/canonicalした
ソフト404になり得る操作を説明します。
(1)中古ドメインを購入した
中古ドメインだと知らずに購入して、自分は新規ドメインと思い込みブログを公開したら、新記事はインデックスされたが、サーチコンソールには大量にソフト404が発生したなどが考えられます。
これは、以前のドメイン使用者と新しいドメイン使用者のコンテンツが違うからです。
対処としては、特に不要で時間経過により安定します。
ソフト404が初期段階で大量に記録されても、しばらく様子をみます。
クロールの問題が発生しないかなど注視するだけにして、放置が基本です。
当然ですが、新しいURLのサイトマップを送信してサイトが切り替わった事を明示的に通知してください。
少し余談を話します。
あまりホワイトと言えませんが、意図的に中古ドメインを買い、以前と同じURLで別のコンテンツをアップロードする方法です。
被リンクを獲得できたりしますので、アルゴリズムとの戦いになりますが、運が良ければ通常の新規ドメインより早くページのランキングが上昇するでしょう。
ですが、Google側もあきらかに中古ドメインを狙ったアルゴリズムを投入し続けていることと、前使用者の自動対策も継続してペナルティを受ける可能性がもあります。
手動対策は、完全に引き継がれます。
中古ドメインにはリスクがあるという認識が必要です。
Google社員の金谷さんも「自分だったら使わない」といっています。
もちろん商標名だったり、絶対にほしいドメインの場合は、リスクを覚悟で購入するのもありです。
アフィリエイトなど運で一発を狙うわけでは無い、企業/ECサイトなどで検討する場合は、中古ドメインを使わない方がよいです。
(2)サイトを削除/修正した
Googleは、インデックスのレコードに更新情報や、その他多くの情報を歴史として保管しています。
サイト運営者がコンテンツをリライトしたり削除したりする行為は、全て理解していると思って良いと思います。
以前はAと書いていた記事に全く違うBという記事に変更した場合、認識するのに時間が掛かり、最初はソフト404が記録されるかもしれません。
そういう意図的な修正の場合は、ソフト404が記録されても問題はありません。
正しくインデックスをするための一時的な状況です。サイトマップを送信したり、URL検査でインデックスの更新をして見守ります。
Aという記事の一部を削除し一部を追加したなど、改善や修正した場合A’と判断され検索順位に優位に働く可能性も秘めています。
記事の改善とは、誤字脱字の修正、内容を読者にわかりやすく修正を行う事です。
しかし一番検索者に喜ばれる修正は時代にあった記事内容に修正することです。
時代にあった修正、例えば2019年に流行った映画のページをarchiveして、2020年の映画のページに書き替えるなどです。
こういう修正は、読者にもGoogleにも高評価を与える可能性があります。
Googleは、インデックスをデーターベースに保存していますので、何処を修正したかもちろん見ています。
タイトルだけとかキーワード追加しただけというスパミーな行為は、SEOのためだけの修正と判断され、逆に順位を下げるかも知れませんし、ソレこそソフト404になるかもです。
(3)全く違う記事に301リダイレクト/canonicalした
全く違うページに正規化やリダイレクトするのは、スパム行為です。
例えば、トップページを検索上位にするために、canonical命令を複数のPageRankが高いページやサイトに設定することがあります。
こうした悪意ある行為は瞬時に見抜かれ、無視されるかソフト404になる事もあります。
また、リダイレクトも同じです。
全く違うコンテンツにリダイレクトすると、不正なリダイレクト扱いされたり、ソフト404になります。
ということでソフト404は原因が多くあり、大量に出なければ、良いです。
エラーがでたurlに対してURL検査ツールを使い、どんなインデックス状態か確認して対処法を決めた方が良いです。
また何かの変更を意図的に行った場合、途中経過でソフト404が記録される事もありますので、意図的で影響が大きくない場合は、長期的に見守る事も必要です。
他の項目にもソフト404は登場しますのでよく仕組みを理解してください。
③サーバーは404を返すがコンテンツは正常表示
これは、珍しいように見えませんか?
実は結構あるのですね。
私はウェブマスターフォーラムで3件は対処したと思います。
主に起きるのが、WordPressでトップページを「固定ページを表示する」に設定しておいて、その固定ページがない場合です。
サイトを構築した初期の段階での話です。
通常は、すぐに気付きますが気づかなければ「1ヶ月ずっとトップページがインデックスされません」などになります。
こうした設定ミスも、URL検査などで調査できますので、必ずトップページや記事ページのHTTPレスポンスを確認する癖を付けておいてください。
単純にレスポンスコードだけ見るのであれば、SEOチェキや、ブラウザのF12を押して出てくる開発者メニューでレスポンスコードを表示するようにすれば見る事ができます。
画面には、正しく価値のあるコンテンツを表示していても、googlebotに404を返してしまうと、インデックスされません。
またインデックスされていても、404を返せば、いくら価値のあるコンテンツでもインデックスから削除されます。
記事を作成したばかり、何かシステム修正をした後など、サーバーのHTTPレスポンスが正しい値かどうか、確認をしてください。
404対策のベストプラクティス
404発生時の対処です。一度作ったページを、気に入らないので削除したなど、こういうページは半永久的にクロールエラー(404)が出る可能性があります。
またページではなく、カテゴリーやタグなど、URLになるものでも記事と同様に発生します。
半永久的に出ますので、どう対処するのかきっちりと判断します。
404が発生するときの対策方法は次の通りです
・代替記事があればリダイレクトする(ベストプラクティス)
・削除している状態が正しい場合は放置する(ベストプラクティス)
・同じURLで記事を書き直す
概ねこのような対処になると思います。
私の指針は、今そのページは無く、ないのが正常であるなら404を返すべきです。
変なリダイレクトを行い、人気の高いページに誘導したりトップページに誘導する必要はありません。
そのURLでは、コンテンツがないという事をGoogleに伝えるのは、正しい行為です。
ただし、一度書いた記事を削除して「新しい改善した記事」を書いた場合、削除した記事のURLから新しい記事のURLに301リダイレクトするのは、正しい行為です。
訪問者にとっても有効なものは、ぜひ実施してください。
404にするか?、リダイレクトにするか?の判断は非常に微妙です。
見る人によっても違いますし、受け取る側によっても違います。
基本的には「同じような内容」であれば、リダイレクトをするのは推奨されますし、実施した方が良いでしょう。
その判断は「記事を書いた人が同じ様な内容」だと判断できるなら、やって良いです。
というか、やりましょう。
問題なのは、不正なリダイレクトというペナルティです。
これは、全く別のコンテンツに誘導(リダイレクト)する方式です。
例えば「ジャガイモのレシピ」のページで人気を集めて、このページとは全く関係ない「カードの契約のページ」等にリダイレクトする等です。
こういったのは、外部から見ても明らかにスパム目的だというのが分かりますので、不正なリダイレクトの適用を受ける可能性があります。
意図的にそういう行為を行わなかったら大丈夫ですので、リダイレクトした方が訪問者のためというのであれば、リダイレクトしてください。
404を明示するのも間違っていないので大切な事です。
一番訳が分からない対応はエラーが出るのでリダイレクトしたい等と考える事です。
実はフォーラムで質問があって、404対策の理由を聞くと、エラーが出るので対処したいと答える方が結構いたのですよね。
このような「意思のない無意味なリダイレクト」は絶対にやめてください。
404でリダイレクトされて嬉しいのは、同じような記事に飛ばされるときだけです。
エラーがウザいというのは、確かにありますが、Googleがエラーとして通知している理由は、今後このURLでコンテンツが再作成される可能性を調べているのです。
もし低品質で削除した等でしたら、同じURLで書き直してみるのはどうでしょうか。
新しいサーチコンソールでは、不必要に404を重大なエラーとして通知しないように取り組んでいます。
404は運営者の意思に影響する部分が大きいと思いますが、一番は訪問するお客様やブックマーク/リンクをしてくれているファンの方々です。
こういった方々に悪い影響を与えないように運営したいですね(*^-^*)
余談ですが、404が大量に発生したことをGoogleが検知した場合、サーチコンソールにメールで通知が来る場合があります。
これを初めて受けるとびっりします。
良質なコンテンツが沢山あるのに、ある日、急に404を大量検出したGoogleは、ウェブマスターの元に沢山404を検出しているけどあなたのサイト大丈夫なの?と心配してくれるのです。
私は、こういう気遣いのできるシステムは、凄く好きです。
ただ、いきなり受け取ると焦りますよね(^◇^;)
もし通知されても、自分で意図的に削除したのなら問題はありません。
しかしサイトの構成変更などでミスをしてしまい、インデックスを消失するような事になった場合、速やかに元に戻してください。
後者の場合も焦る必要はないですよ。
検索結果に全く出なくなる可能性もあります。
それでも、過去の順位をGoogleは、ちゃんと覚えておいてくれるのです。
概ね2週間を超えると本気で削除を行いに来ますので、いくら「覚えておいてくれる」と言っても、早めの修正を行うのが良いです。
クロールエラーは原因や環境によっても、発生の仕方がいくつもありますので、Googleのヘルプは一通り見ておいてください。
info: site:の意味と使い方
info: は、2019年3月廃止されました。とても残念ですが、info:で確認できた機能はURL検査ツールに移行しました。
site: 演算子は、当該サイトのインデックス一覧や概要を表示するものです。
検索結果は、一覧で表示されますので、例えばマイナス(- その文字列を含まないという意味)やキーワード、またinurl:(URL内にこの文字列を含むという意味)などと併用してインデックス状態を確認する事が出来ます。
気をつけて欲しいのは、site:はとてもいい加減で、インデックス個数はめちゃくちゃで表示されます。
SERP’sに表示されるので、インデックスされている?と思っても、普通のキーワードで検索すると出てこなかったりします。
このようにsite:は正確性に欠いている演算子です。
使用は、インデックスのおおまかな状態を知るというレベルに、とどめておいてください。
正しいインデックス状態を確認するには、必ずURL検査ツールを使用するように身につけてください。
リダイレクト先の確認や正規化の確認は必ずURL検査ツールを使ってください。
URL検査ツールの使い方
URL検査ツールは、検査対象のURLがGoogleのインデックスレコードに、どのような状態で登録されているのか調べるツールです。各種トラブルシューティングを行う場合、最初に使うツールと言ってもよいでしょう。
URL検査ツールへのアクセス方法は次の3種類です。
・最上部にある入力フォームにURLを入力する
・左側にメニューより「URL検査」をクリックする(上のフィールドに移動するだけ)
・各種インデックスカバレッジの調査でURL検査を選択した場合、メニューに出る
URL検査ツールへのアクセス
こんな感じでとても目立ちます。
URL検査ツールでわかることは次の3つです。
・インデックスの登録状態
・カバレッジ
・拡張(モバイルユーザビリティ、AMP、リッチリザルト関連)
インデックスの登録状態を表示
この順番で表示されます。
表示は折りたたみ式になっていて、必要な項目をクリック・拡大して見ることができます。
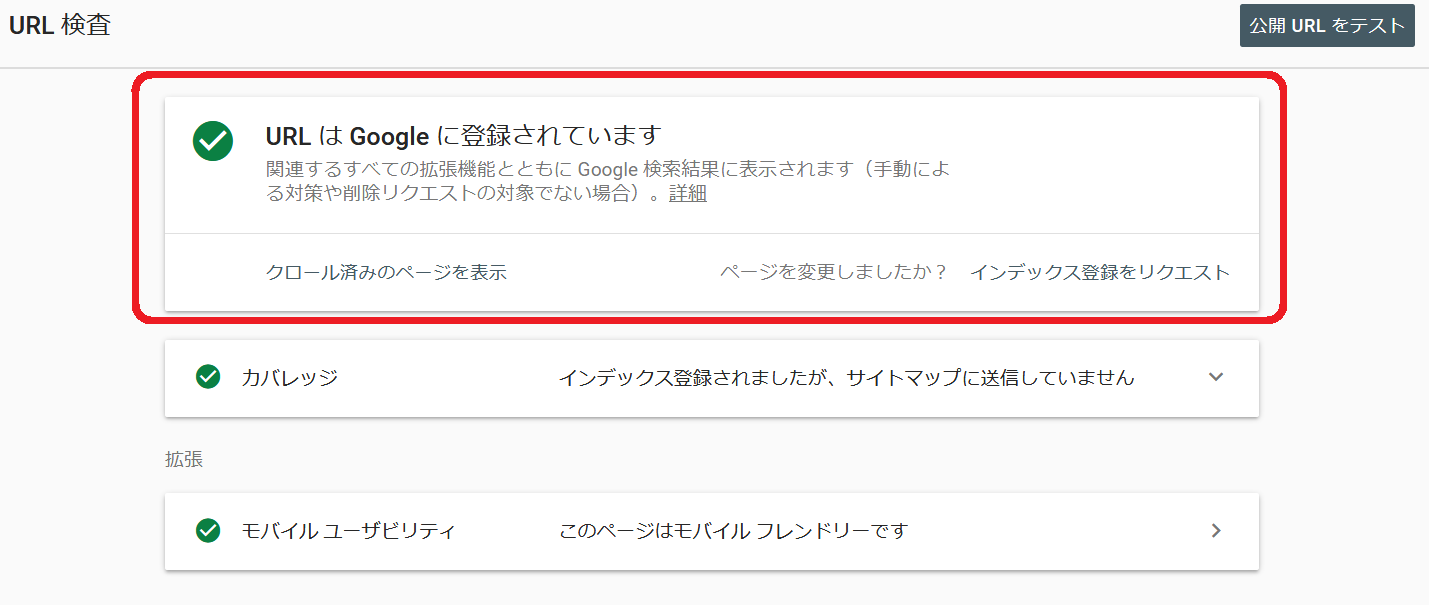
最初に表示されるのはインデックスの登録状態です。
インデックスの登録状態は次の4種類で表示されます。
- Googleに登録されています インデックスが正しく登録され、問題ない状態です。AMPやレシピなどがある場合問題なくマークアップされています。
- Googleに登録されていますが問題があります インデックスは登録され検索結果に出る可能性はありますが、一部の機能がエラーか警告がでて正しく動作しない可能性があります。
- Googleに登録されていません。インデックス登録エラー インデックスに登録されておらず、1章で説明しているインデックスカバレッジで「エラー」が記録され、それが原因であると推測できます。
- Googleに登録されていません インデックスに登録されていませんが、サイトの運営者が意図的にnoindexにしていたり、canonicalで正規URLを指定していた場合、発生します。コントロール内であれば問題ありません。
この右側にある「インデックス登録をリクエスト」ボタンを押すことにより、ダイレクトにインデックスに送信します。
(旧来のFetch as Googleと同機能)
次はカバレッジです。
以下のに示すように大量の情報を表示します。
URL検査ツールでわかるカバレッジの状態
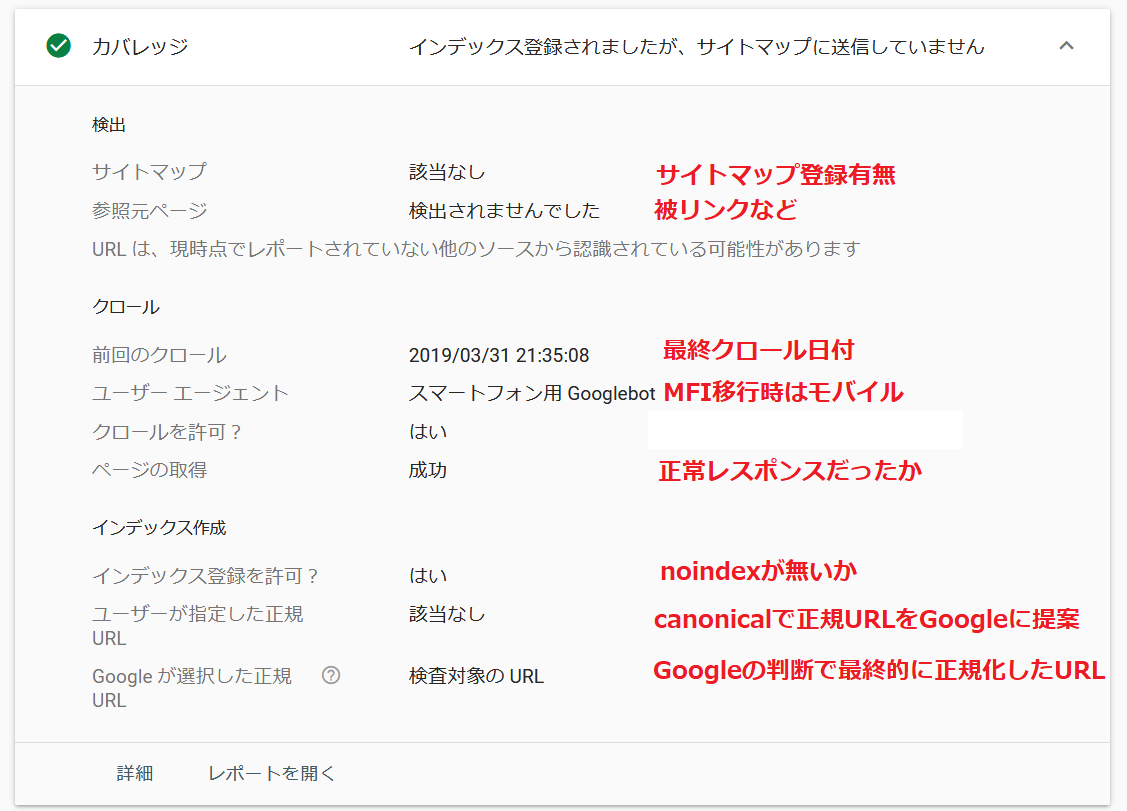
- サイトマップ 検査対象のURLがサイトマップで送信されているかどうかの確認です。
- 参照元ページ Googlebotがどこかのリンクをたどって得たURLの場合その内容が表示されます。
- 前回のクロール 検査対象のURLをGooglebotが最終クロールした日本時間です。
- ユーザーエージェント インデックス登録したのが、スマホのbotかPCのbotかを表します。MFIに移行していると全てスマホのbotになります。
- クロールを許可 robots.txtでクロールがブロックされていないかどうかを検出します。
- ページの取得 HTTPのリクエストに対する応答が、正しく行われたかを表示します。
- インデックス登録を許可 noindexでインデックス登録をブロックしているか否かを表示します。ただしクロールを許可の項目でrobots.txtによりブロックされていたらこの項目は無条件で「はい」になりますので、注意してください。
- ユーザーが正規化したURL 検査ページにcanonicalがあると、Googleに正規URLを提案したことになり、ここに表示されます。
- Googleが選択した正規URL Googleが最終的に正規化したURLが表示されます。
canonicalで提案していなくても、重複ページがある場合、Googleにより自動正規化されたURLも表示されます。(検査対象と同じ場合は、検査対象のURLと表示)
最後は、拡張(モバイルユーザビリティ、AMP、リッチリザルト関連)です。
- モバイルユーザビリティ モバイルユーザビリティでエラーが表示されているなら、何よりも先に修正すべきです。
- AMP マークアップしたAMPが正しく登録できたかどうか確認できます。
- リッチリザルトなど 製品または求人やQ&A、レシピなど、構造化データをマークアップしていると、検索結果にリッチリザルトが表示される可能性があります。
モバイルフレンドリーでないサイトは、著しくランクを下げられますので、優先順位を上げて対応してください。
工数などですぐに対応できない場合は、ランキングを犠牲にするしかありません。
世の中のほとんどのサイトがモバイル対応し、50%以上の人がモバイルでサイトを見ています。
その中でモバイル対応しないのは、時代と逆行していると考えてください。
モバイルフレンドリーではありません
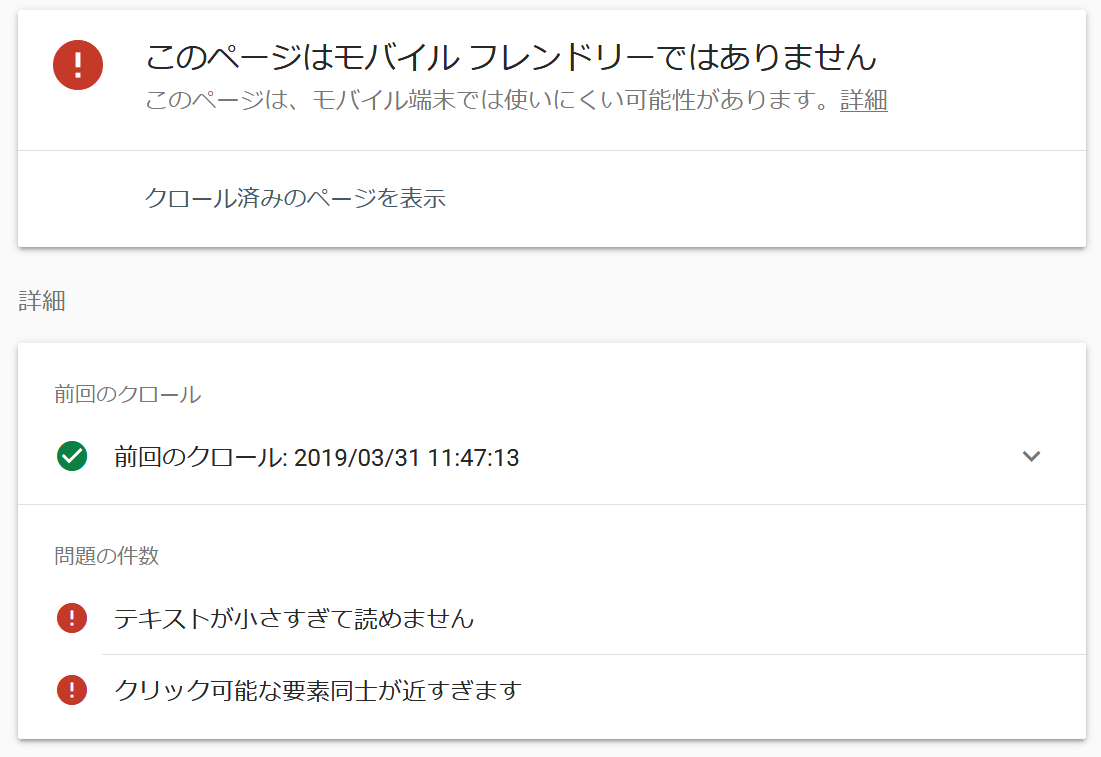
ただし、インデックスの送信機能がついていないため、AMPバージョンのみ修正した場合、通常ページでページ更新のリクエストをして待ちましょう。
AMPのマークアップが成功している場合
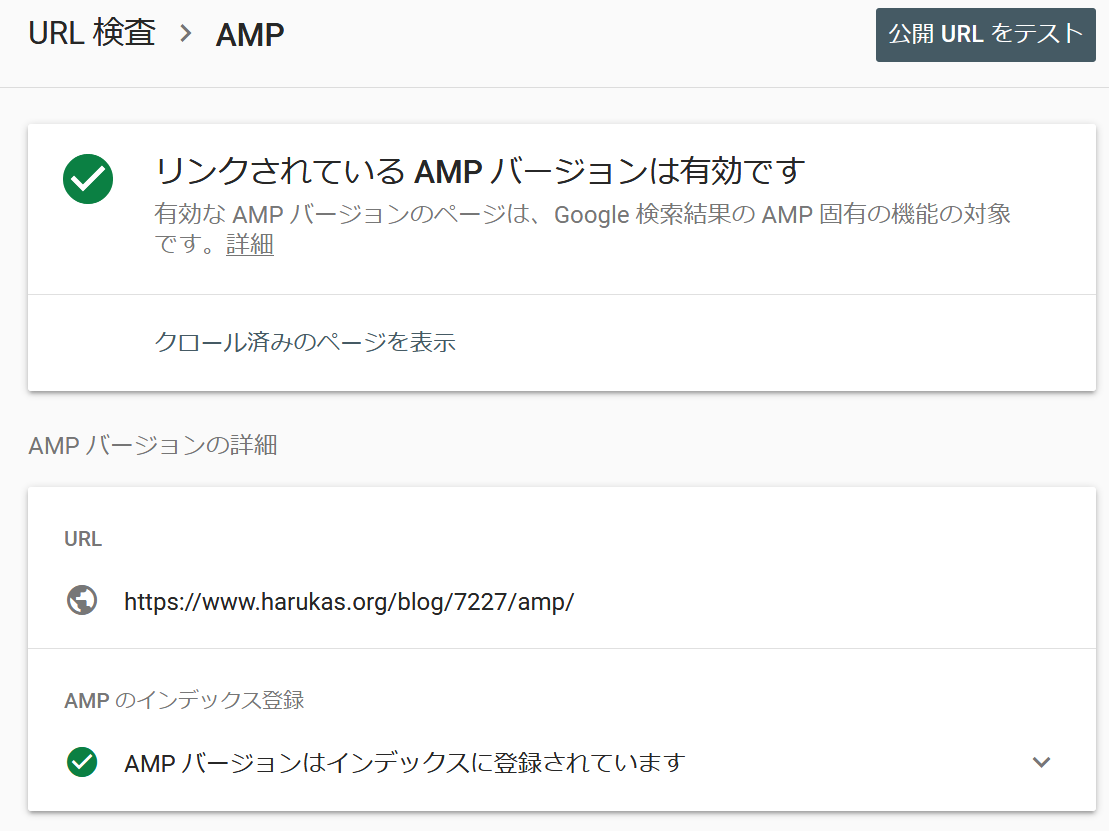
マークアップを多くするほど、適した環境で構造化データが使用されます。
それらのインデックス登録状態を見ることができます。
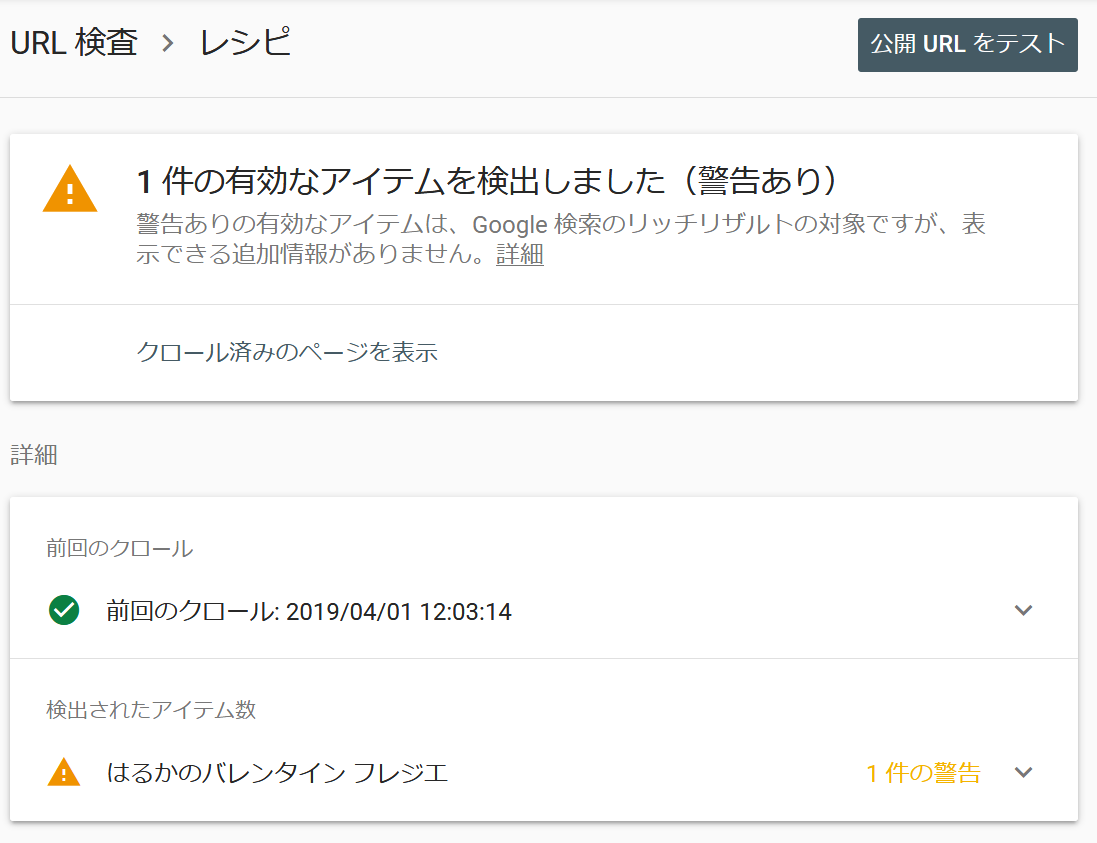
以下は、レシピで「ビデオ」のマークアップがないので警告を受けた状態です。
レシピのマークアップでVIDEOが無く警告を受けている状態
URLを入力するだけで、これだけの情報がわかります。
また、トラブルシューティングを行うときもとても優秀なツールです。
インデックスが何かおかしい?と思った時は、真っ先に実行するツールです。
便利に使いましょう♪
有効(警告あり)がレポートされた場合の確認項目と対処
有効(警告あり)のレポートで表示される物は、現在1種類しかないようです。有効という文字が使われていますが、インデックスに登録できなかったものも含まれる可能性があります。
有効(警告あり)のレポート

では、具体的に発生する警告内容を見てみましょう。
robots.txt によりブロックされましたが、インデックスに登録しました
これ、知らなかったら何の事か分からないですよね。まず大前提として、以下を確実に覚えてください。
①robot.txtでクロールを阻害する
→Googlebotはサイトを巡回する事ができない。
ただしインデックスは行う。
②metaタグなどでnoindexを指定する
→Google/Bingに対する絶対命令であり解読された場合インデックスを消去する。
①と②は全く別の話です。
クロールを阻害する=インデックスさせないと勘違いしている人がいます。
クロールが阻害されると確かにインデックスするのは難しくなります。
しかしGoogleは充分に人気が高く、リンクしているサイトが多い場合、robots.txtでブロックされていてもその内容をインデックスする事があります。
Googlebotがブロックされるとクロールできませんので、その時のタイトルは「サイト名」や「アンカーテキスト」になる事が多いです。
meta説明文は、クロールできないので、表示しません。
検索結果を、具体的に見てみましょう。
robots.txtによりブロックされましたがインデックスに登録しましたの状態で私のサイトを検索

自分のサイトが、このような検索結果になっている場合、殆どがrobots.txtでブロックされているにも関わらずインデックスされている状態です。
インデックスさせたくない場合は、robots.txtのdisarrowを外しnoindexを使う事を検討してください。
また、noindexとrobots.txtによるブロックの両方設定していると、noindexと書かれたコードをクロールできませんので、インデックスされるという真逆の行為になります。
本当に気をつけてください。
サイトの特性により、メタタグでnoindexを指定するためhtmlを挿入することが難しい場合もあると思います。
そのときは、htmlを修正せずにnoindexにする方法もあります。
HTTPのレスポンスヘッダに、X-Robots-Tagを挿入する方法です。
この方法を使えば、ディレクトリを一括でnoindexにする事もできます。
HTTPヘッダはPHPやJS、httpd.conf(.htaccess)で簡単に生成できますが、扱いには注意してくださいね。
くれぐれも、検索結果に表示したくない状況が発生したら、robots.txtを使用するのではなく、noindexを使用する事を頭に入れておいてください。
もし、検索結果に機密情報や個人情報などが表示されてしまった場合は、noindexを付ける等の施策より先に、すぐに表示を削除してください。
URL削除ツール
このツールは非常に強力です。
誤った使い方をするとインデックスに致命的な影響を与えます。
緊急時のみ、速やかに使えるように仕様と使い方を理解しておいてください。
注意点は、このツールは一時的に検索結果から削除するものです。
検索結果から削除されたからといって、個人情報や機密情報がWebで通常閲覧できるようであれば、全く意味はありません。
確実にファイルなどを削除し、URL削除ツールで使用したURLが404になる事を確認してください。
およそ90日で復活してしまいます。
なお、ウイルス感染したインデックスや、間違ったものをインデックスしてしまって削除する目的で、このツールの使用は許可されていません。
「URL削除ツールの誤った使い方」
も充分に理解しておいてください。
公開前サイトのベストプラクティス
公開前のサイトのベストプラクティスについて説明します。サイトを非公開にしてテストで作成し、ある日を境に公開したいという場合、どのようにしますか?
こういう質問をすると、robots.txtでクロールを阻害するという人も多いかと思います。
しかし、先ほどの例の通り、robots.txtでクロールをブロックする行為は、インデックスさせないという命令とは違います。
もしかしたら、テストサイトがインデックスされてしまう可能性があります。
では、どのようにしたら良いか?です。
もう一つのインデックス阻害方法である、noindexを使えば良いのでしょうか。
いいえ、私はnoindexを勧めていませんし、使うべきではないと思います。
将来的に一切インデックスさせる必要がない場合、もちろんこれで良いのです。
しかし、将来的にページをインデックスする予定がある場合、noindexを使ってはなりません。
理由は、noindexを指定するとそれを解除するのに時間が掛かるからです。
サイトが新規オープンする日に素早くインデックスさせたい等のベストプラクティスは、アクセス制限を使用することです。
httpd.confやnginx.confなどでアクセス制限を設定しGooglebotに対して403(401)を返却するようにします。
これにより、解除してインデックスに送信を行えば、素早くインデックスする事が可能です。
ただしこれには条件があり、短期の場合のみ有効です。
一ヶ月を超える場合、ずっと403を返し続けるとそのサイトは、永遠にそうだと思い込みクロールバジェットを減らされる可能性があります。
テストはできる限りローカルで行い、本番環境はアクセス制限を付与して短期間公開/確認するのが最適な方法だと思います。
オフラインでサイトが完成していてオンラインでテストする必要がない場合は、アクセス制限ではなくサーバーエラーの503を使うことも可能です。
このコードを受信したGooglebotは、サイトが一時的に閲覧出来ない状態だと認識して、回復するまで何度か定期的にトライしてくれます。
従ってうまく使えば、新規サイトのオープンに利用する事も可能です。
(もちろん、運営中の不具合で緊急的にサーバーを停止しなければならない等にも使用できます)
503も403/401同様、概ね2週間以上(503は1週間以上)続ける物ではありませんので注意してください。
そのほかの警告があるのか、ヘルプの情報が少ないので、現状「警告」はこの項目だけ説明しました。
次は、インデックスの除外についての説明と対策です。
インデックス除外の項目説明と対策
除外の項目に表示されているのURLはインデックスに登録されません。殆どがウェブマスターの指定によるものですが、インデックスに登録することが妥当ではないとGoogleが判断したものも登録されません。
除外

「除外」の基本的な見方は「すべての送信済みページ」から見るのがよいと思います。
いろいろなケースにあてはまるかわからないので、はるかはこのような見方をしているんだな程度でお願いします。
何故サイトマップで送信した物を優先してみるか?です。
それは、サイトマップで送信する=インデックスへの登録を要求だからです。
ウェブマスターがインデックスに登録したいと思ってサイトマップに追加しているのですから、そのURLがなんらかの原因でインデックスされていない場合、問題の優先順位を上げる必要があります。
よって、送信済みのページから見た方が見やすいかなあと思いました。
私の理想は「インデックスはウェブマスターがすべてコントロールする」です。
正しいサイトマップを送信することで「除外」の項目についても見やすくなります。
では、代表的な発生原因と対策を見てみましょう。
noindex タグによって除外されました発生の対策
noindexタグによってインデックスが除外されたレポートです。クリックすると詳細情報を見ることができますので、ウェブマスターがコントロールしたURLがnoindexになっていれば問題ありません。
この項目があるからといって「ゼロにしよう」だとかいう行為は、全くの無意味で、サイトにとって悪い事ばかりです。
ちゃんとコントロールが働いているか、確認するレベルにとどめましょう。
この項目は、確認がメインの項目です。
設定ミスをしない限り、突然増えることもありませんので、noindexを扱うシステム変更をしたときは、注視するようにします。
サイトを構築したばかりのときは「すべての送信済みのページ」に切り替えて、送信したURLがnoindexになっていないか、一定期間監視します。
サイトマップを送信していない場合は、必要なURLがnoindexになっていないか念のため全て確認します。
noindexは、head内に記載するのが正しいhtmlです。
しかしGoogleは、bodyタグの中に入れても機能します。
noindexの説明をするページがnoindexになるのは、非常に間抜けですのでもしそういったコンテンツがあれば括弧をエンコード文字にするなどの対策を行います。
noindexを指定するようなコメントがもしあった場合、公開承認をしないよう注意してください。
(WordPressや一般的なシステムではhtmlが記述できなかったり自動エンコードされたりするので安全です)
ページ削除ツールによりブロックされました発生の対策
これは、URL削除リクエストにて該当URLを削除したものが表示されます。私は、このツールを簡単に使うべきではないと、いつも啓蒙しています。
Googleのヘルプでは、インデックスをクリーンナップするなど、誤った使い方を禁止しています。
このツールを使うシチュエーションは、運営者のミスで個人情報を漏洩してしまったり、機密事項を漏洩してしまったりして、すぐにでも情報を削除しないと不利益を被る場合です。
なぜ乱用してはならないか?
それは乱用するとインデックスしたいページが、このツールの影響でインデックスできないという現象が発生するからです。
インデックスをコントロールするとは、こういうツールを使うことではありませんから、決して誤解しないようにしてください。
サイトを運営していると、間違って変なページをインデックスしてしまうことがあります。
その場合、影響が軽微であったら処理をGoogleに任せるのが一番の得策となるわけです。
間違えたら、消せばいいや程度でURL削除ツールを使用すると、取り返しの付かない状況になる可能性がありますので、このツールを使うときは、特に慎重になってください。
URL削除ツールのブロックは、通常運用をしていたら、表示されません。
ツールを使用して、削除が実施されたら、そのURLが表示されるはずです。
ただし、通常404も同時に行うはずですから、将来的(直近なら90日後)には404の方だけに記録されるかもしれません。
もしそうなっても、インデックスはコントロールしていますので、自分の行った作業の結果と一致していれば、問題ありません。
robots.txt によりブロックされました発生の対策
ドメインのトップに設置してある、robots.txtは、Webサイトにやってくるクローラーにあらゆる指示を与えることができます。Googleのように真面目に従うのもあれば、完全に無視するMJ12botなどがあります。
問題なのは、クロールしてインデックスされなければならないコンテンツにブロックが指定されていて、インデックスされない事です。
そういったトラブルを、このレポートでは発見する事ができます。
私からの助言はrobots.txtは使う必要はありません。
え?と思いますか?
では、何故いるのでしょうか??
大手ブログや超超大規模サイト(インデックス数が数百万以上)などは、限られたクローラーのリソースをうまく使い、クロールさせる必要があります。そのリソース管理(クローバジェット管理)が必要です。
リソースをうまく管理するのに、robots.txtは役立ちます。
つまり一般サイトは、そんな対策は必要ないので不要であるという事ですね。
WordPressでは、robots.txtが勝手に作成されますが、特にそれを使用しても問題はありません。
(私はWordPressが作った物は使っていなく、その設定はありません)
そもそもクローラーにアクセスされて困るページは公開するものではありませんね。
ということで、このレポートが記録されている場合は、詳細を見てURLを確認しrobots.txtを確認してください。
サーチコンソールのURL検査ツールや、その他のGoogleのツールでもブロックは確認できます。
繰り返しますがGoogleに表示されたくないコンテンツがある場合は、noindexを使用してください。
また、アクセス制限を使うのも効果的です。こちらは403のエラーが記録されるかもしれませんが、コントロールしていれば問題ありません。
サイトマップでインデックスを要求しているディレクトリが、ブロックされているとここでレポートされます。
大量に発生した場合は、意図しないシステムでrobots.txtが変更されている可能性があります。
WordPressでは、設定→表示設定で「検索エンジンがサイトをインデックスしないようにする」という説明があります。
WordPressの設定→表示設定メニュー
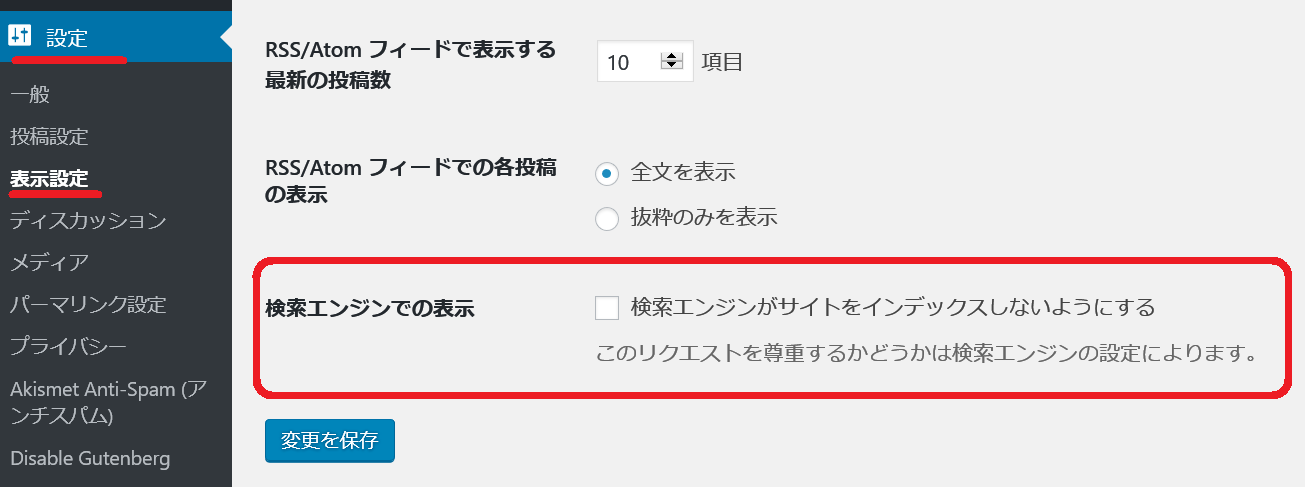
このチェックボックスをONすると、robots.txtが自動的に書き替えられ、Googlebotがブロックされる設定が追加されます。
ちなみに、この説明は間違っています。
正しくは、robots.txt変更し検索エンジンが巡回するのをブロックします。
です。
3度目の説明ですが、robots.txtで検索エンジンをブロックする事は、サイトをインデックスしないようにする事ではありません。
この指定をしていると、逆にインデックスされる可能性もあるという事を理解しましょう。
Googleは、クローラーがアクセスできなくても、大量のリンクがあるURLは、インデックスしようとします。
当該URLを一切インデックスしたくない場合は、noindexを使いましょう。
WordPressならheader.phpにnoindexが機能するタグを入ればOKです。
さてクロールの実情を話しますと、robots.txtに従わないクローラーは当たり前ですし、サイトのパフォーマンスを気にして設定するのも意味がありません。
理由は、従わない下品なクローラーが圧倒的に多いので従うクローラー(Google、Yahoo、Bing)にブロックの設定をしてても、パフォーマンス対策が目的なら全く意味がないからです。(紳士なクローラーが3社で10回として指標を30としたら、下品は500程度です。500をブロックすれば効果はありますが、500は無視して30に何必死で対応しているの?という感じです)
下品なクローラーは何をしてるかですって?
ええ、ハッキングできるか試しているのです。
例えば脆弱性のあるWordPressのバージョンを使っているとか、バックドア(既にハッキング済みで運営者が気付いてない場合、そういったサイトを探す)があるサイトを探しています。
全く面識がない企業のサイトです(笑)
こういう情報を無料提供しているのは好きなのでリンクしておきます。
WordPressワードプレスセキュリティースキャナー
こういうサイトで、外部から問題があるかどうか見てくれます。
あ、言い忘れましたが、ここで真っ赤に表示されるからといって、焦る必要はないですよ。
多分そういった方は結構いますので、心配な方は有識者に確認してみてください。
WordPressのフォーラムを利用するのもお勧めです。
robots.txtでのブロックが検出されて困っている場合は、ルートドメインのrobots.txtを確認しましょう。
そしてファイルを編集し、Disallow: の項目を削除しましょう。
クロールエラー発生の対策
クロールエラーは、4xx/5xxなどの発生でレポートされます。しかし、他で検出するレポートとの差別化が旨く出来ていないように思います。
例えば、404(ファイルが見つかりません)で説明します。
この場合、クロールのされ方と設定状態によって、次の様にレポートされます。
1)ステータス:除外 型:クロールエラー
2)ステータス:除外 型:見つかりませんでした(404)
3)ステータス:エラー 型:送信された URL が見つかりませんでした(404)
1のクロールエラーは、現在ライブでリンクされていたりGooglebotが外部からの被リンクに連動したりしてサイトがクロールされた時に検出するエラーです。
基本的には、サイト内の問題ではない可能性が高いです。
2は、以前使用していたリンクや記事を消してしまった。
またサイトマップで送信していたが、消してしまったなどを定期的にクロールしてコンテンツが復活していないか確認するときに検出したレポートなどです。
3は、サイトマップにURLを記載してインデックス登録要求をしているにも関わらず404になっている場合です。
このように、同じエラーでも設定などによって変わってきます。
また、レポートも検出したbotの種類に依存しますので、ヘルプにも詳しい説明がありません。
まずは、除外のクロールエラーが発生するURLは、サイトとして存在するべきURLか否か確認します。
通常は、発リンク側のタイプミス等ですから、ウェブマスター側が何か対策をする必要はないと思います。
URLを見た瞬間に判断できると思います。
この解析には、あまり体力をかける必要はありません。
クロール済み – インデックス未登録発生の対策
これが発生する状態は、検索エンジンがクロールはしているがインデックスには登録されていないという状態です。検索エンジンにインデックスされる前の課程ともいえます。
さきに検索エンジンの動作を簡単に説明すると次の様になっています。
1)クロール
2)インデックス
3)ランキング
※この処理を詳しく知りたい場合、私が超詳しく書いています。
クロールバジェットをコントロールする事の重要性について
この順番で処理を行い、検索キーワードに適した検索結果を画面に表示しています。
サイト側が、クロールできなければ、検索エンジンに表示されるはずもないですし、インデックスされないと表示も出来ません。
インデックスされても、キーワードとの関連性がないとランキングされないため、検索エンジンには表示されません。
クロール済みインデックス未登録になる状態とは1)と2)の間の状態だと思っていただければ良いです。
放置しておけば、2)になる可能性もありますし、永遠にこのままの可能性もあります。
(※全くの余談ですが「検出 – インデックス未登録」という1)より前の状態も存在します)
サーチコンソール全般に言えることですが、検出はあくまでクロールした段階であって、リアルではないのです。
つまり、実際はインデックスされているにもかかわらず、サーチコンソールの情報が古くてインデックスされていないと表示されることがあります。
リアルの状態が知りたい場合は、発生しているURLをクリックして、URL検査を行い「公開URLをテスト」でライブテストしてください。
私の現在の調査では「クロール済みインデックス未登録」は、低品質なコンテンツでも発生することを確認しています。
低品質といっても、RSSのURLとかメディアページなど、インデックスされても意味の無いページです。
もし、重要なコンテンツが、このステータスになっている場合は、インデックスへの登録を即す操作を行うのではなく、一度コンテンツを見直してみてはどうでしょうか。
またGoogleのウェブマスターガイドラインに反するようなコンテンツは、手動対策が発生するより前に、クロールが遅くなったり、クロールバジェットを減らされたりします。
低品質のコンテンツはクロールバジェットを減らす
という訳ですね。
この状況が発生すると、インデックスの途中段階で処理をやめてしまうので、「クローズ済み – インデックス未登録」になるかもしれません。
ガイドラインに違反するようなコンテンツや無限スペースなどクロールに問題ありそうな情報はすべて私が書いた以下のサイトに載っています。
クロールバジェットをコントロールする事の重要性について
上述の記事では、クロールバジェットを減らす原因や対処、また公式の内容から私の深掘りまで、かなり深いです。
インデキシングは、いろいろな原因で問題が発生しますので、状況を的確に判断することが大事です。
すべて、これが原因だ!と決めつけるのでは無く、優先順位を決めて少しずつ対策すれば良いと思います。
私はエラーの数の多さで大まかに判断できると思っています。
想定は、次のふたつです。
・クロール済みインデックス未登録が大量
原因は、サイトが若い(まだ公開して日が浅い)、人気が無い、など様々な理由でクロールバジェットを減らされている可能性があります。
クロールバジェットの記事をよく読んで、対策を検討してください。
この場合「検出 – インデックス未登録」も発生する可能性があります。
対策は、品質改善のみです。
ただし、ツールやデーターベース関連のサイトは、もともとインデックスが難しいです。
クロールバジェットの記事をよく読んで、パラメータと固定URLの使い方、またサイトマップの送信などを適切におこなってください。
・クロール済みインデックス未登録が非常に少数
原因は、特定のページの品質問題だと思います。
つまり、「このページだけ」クロールやインデックスを「遅く」されています。
対策は、しなくても全体が影響することはありません。
RSSフィードのURLなどインデックスしても意味ないページであれば、無視してOKです。
メディアページなど価値が低いページも同様です。
もし、重要な記事でこのステータスとなり、修正を考慮されている方へアドバイスです。
WordPressなどのCMSを使われている方は、すぐに改善出来ないので削除してしまおう考えるかもしれません。
そういう人は、削除では無く記事を非公開に設定してください。
削除すると、折角の記事が台無しです。
非公開にして、時間があるときに改善してから再公開すれば良いのです。
そもそも記事を削除して品質が上がるというのは、私はよく分かりません。
削除などは安易に行う物ではないです。
「クロール済み – インデックス未登録」でレポートされたコンテンツは、検索結果に表示されている場合もありますが、表示されない場合もあります。
検索エンジンにインデックスされ、表示しているか否かを確認するには説明の通り「URL検査ツール」で確認してください。
URL検査などで調べて、インデックスされていないと判明しても、安易に削除したりしないでくださいね。
SEOの基本は、想定以外の方向に動いたら、元に戻すですから。
サーチコンソールのチェックが品質と全く関係ないかもしれません。
そういうときに、元に戻らない様な施策を実施するべきではありません。
私は、記事の削除でドメイン価値向上は、真っ向から否定しています。
そんなのでドメイン価値が上がるなら、不正記事を自動作成で1万ページくらい作ってGoogleに認識させた後、削除しますわw
引き続きこのレポートは、注意深く見守ります。
代替ページ適切なcannonicalあり発生の対策
このレポートは、canonicalを正しく検出して正規化が成功している場合です。
私の場合、ほぼampのオリジナルページ(Googleやキャッシュで無く、制作者のAMPページ)やパラメータ付きのURLが検出され、正しく正規化が出来ている事を確認できます。
URL検査ツールを使うと、どのページに正規化されているのか、確認する事も可能です。
ampのページなら、ampの付かないオリジナルページが検索結果に表示されるはずです。
このレポートは確認がメインなので、常時監視する必要はありません。
それではついでにcanonicalの使い方について説明します。
canonicalの使い所は次の通りです。
・自己参照設定を行い付随するパラメータの排除
→パラメータが付与された複数のURLを排除するため、自分自身をcanonicalする
・ECサイトで色だけ違う商品などを統合する
・小説サイトなどで1ページ目をインデックスさせる
・上と似ているがページャーの設定
・モバイルページの正規化
・その他
など多数の用途があります。
canonicalは、canonicalする側とされる側に分かれます。
canonicalされた側は、インデックスされることはありません。
つまり、非正規ページをインデックスから消すという行為も入っていることに注意してください。
canonicalは、悪意のない使い方をしていれば、問題はありません。
リダイレクトと違い、ブラウザはページを表示することが出来ます。
そのため、Googleに対しては、canonical命令はウェブマスターからGoogleへの提案でしかなく、絶対命令ではありません。
絶対命令ではないため、canonicalを記述しているのに、その通りに動作しない事があります。
これはアルゴリズムにより決定されているのでウェブマスター側から操作はできません。
(ウェブマスターからの提案の結果、Googleがどうしたのかは、URL検査で分かります)
注意が必要なのは、canonicalの無限ループや、1つのURLを複数のページにcanonicalする命令が入っているなどです。
このような使われ方を発見次第、canonicalは動作しなくなります。
canonicalでも、301リダイレクトでも良い場合は、301リダイレクトを優先するように設計しましょう。
301リダイレクトはGoogleへの提案ではなく、Googleもブラウザ閲覧者も強制的にリダイレクト先のページを表示します。
あと詳しいことは次の重複ページの項目で説明します。
重複しています発生の対策
重複しています、は次の2種類があります。1)ユーザーにより、正規ページとして選択されていません
ウェブマスターが明示的にcanonicalを記述しておらず、URLは違うのに同じコンテンツが複数検出された場合にレポートされます。
このレポートが発生した場合は、いくつかあるページのうち、どれが正しいページかというのをウェブマター自身が判断して、canonicalを付けるようにしましょう。
同時にシステムによって重複ページが出来ないようする対策も検討した方が良いです。
ただし、優先順位は付ける必要があります。
ランキングに全く影響を受けないような問題に対しては、優先順位を最低にしてもかまわないと思います。
GoogleはシンプルなURLを自動的に正規化するアルゴリズムです。
正規URLを選定する場合も、それを考慮するのが良いと思います。
2)Googleによりユーザーがマークしたページとは異なるページが正規ページとして選択されました
ウェブマスターが明示的にcanonicalを記述しているが、Googleが別のページを正規ページだと認識した場合レポートされます。
WordPressでは、プラグインやテーマによって、自動的にcanonicalが入る場合があります。
よって、ウェブマスターが意識せず2になっている場合もありそうです。
なんらかの問題でウェブマスターが非正規ページにしたいにも関わらず、正規ページになっている訳ですから、内容を充分に確認する必要があります。
忘れてはならないのは、URLは検索結果に表示される可能性が非常に高いです。
検索エンジンを利用するお客様に非正規ページを覚えてもらうのは、良くないでしょうね。
それでは、重複ページの全体的な問題の確認/回避方法を説明したいと思います。
重複と一言に言っても、システムで自動的に生成されるものから、こちらの意図とは無関係に勝手にスクレイピングされ、盗み取られるまで、沢山の種類があります。
また、検索に全く影響ないものから、致命的なものまであります。
それらを、まとめてみました。
重複コンテンツの対策について
私がキーワードの重複で一番問題視しているのが、作成者が気付かずに記事間でカニバリゼーションもどきが発生している場合です。
※Google公式情報にカニバリゼーションの定義はありません。
※そんなアルゴリズムは、みたことがありません。
私は、カニバリゼーションなど存在しないというスタンスです。
しかし、よく話題になることがあり、検索結果に期待した記事が表示されないという事も聞きます。
(マーケティング用語であるカニバリゼーションは、共食いという意味です。簡潔にいうと二兎を追う者は一兎をも得ずということわざに近いです。)
SEOに照らし合わせて考えると、複数の記事がキーワード間の情報を食い合い、検索結果に悪影響を及ぼすという意味で使っているのでは無いかと想定します。
この問題に近しい、実際に起こりうる問題を説明してみようと思います。
まず、問題が発生するキーワードを想定します。
例では、「クッキー」というキーワードにします。
自分のサイト内(ドメイン内)で、キーワードの価値をGoogleがどのように評価しているのか、簡単に調べる方法があります。
harukas.orgでクッキーというキーワードをGoogleがどのようにランキングするか
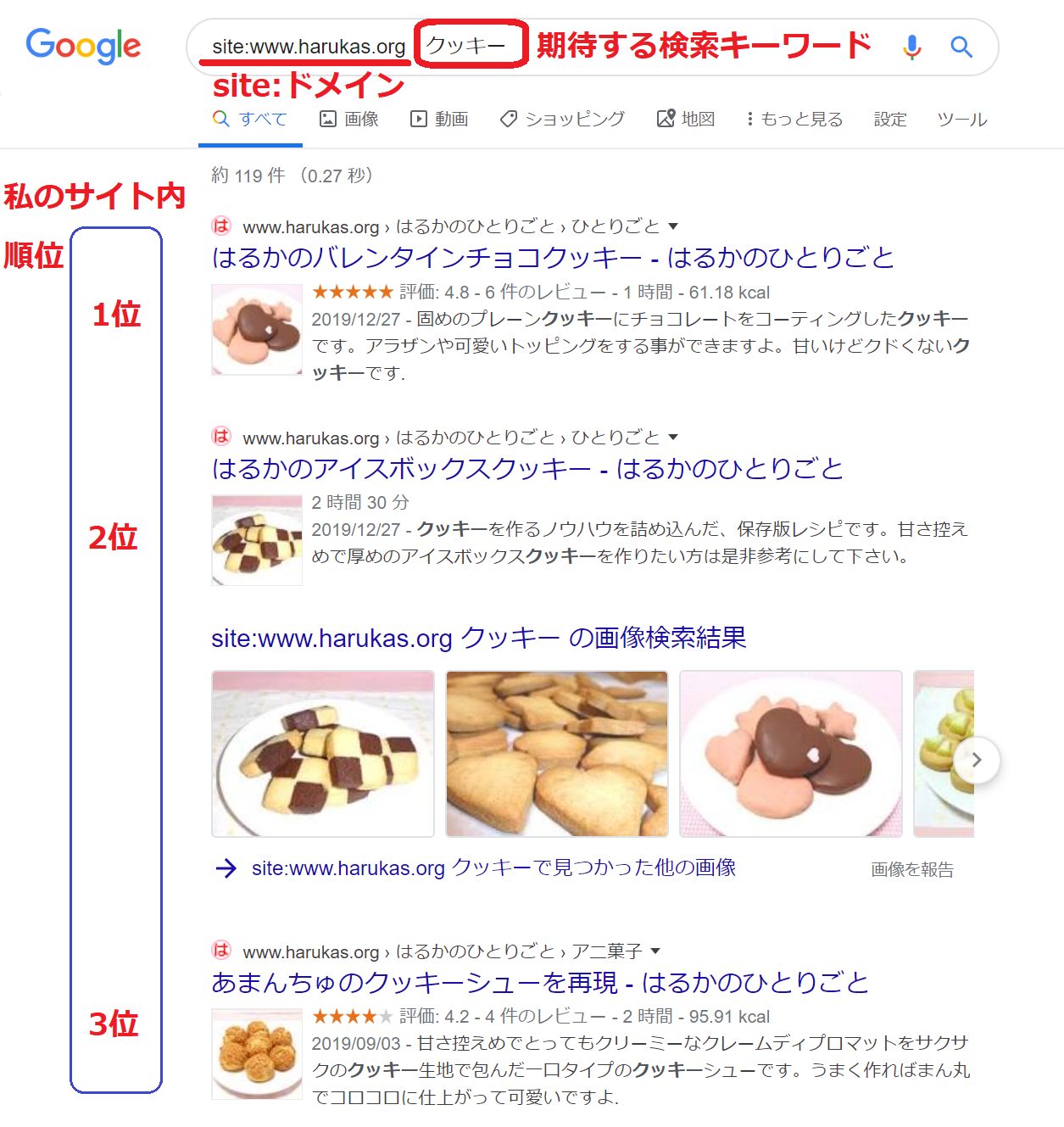
Googleが記事に対して、キーワードの価値としての重み付けを
1位:バレンタインクッキー
2位:アイスボックスクッキー
3位:あまんちゅのクッキーシュー
と判断しました。
記事内のキーワードの登場回数や200以上のアルゴリズムが判断した結果と言えるでしょう。
この1,2,3位はとても複雑なアルゴリズムで算出されています。
検索意図が~とか、簡単な話では無いです。
ですが、タイトルにキーワードを入れたり、商標を入れたりしてある程度自分で順位をコントロールすることができます。
このコントロールをちゃんと行っているサイトは、どんなに同じカテゴリのキーワードを量産しても大丈夫です。
コントロールは重要と言っても、下げたい記事を削除したり(←あり得ない施策)、重要なキーワードを削除したりするのではなく、上げたい方に良質なコンテンツをさらに追加するという「改善」が望ましいです。
通常は、コンテンツを作成するときにある程度キーワードを意識することと、既にサイト内にある別記事との差別化を充分行うことでコントロールは可能です。
では、キーワードの重複で発生する実際の問題を見てみましょう。
一般人が通常の検索で使用しそうな「はるか クッキー」の検索結果
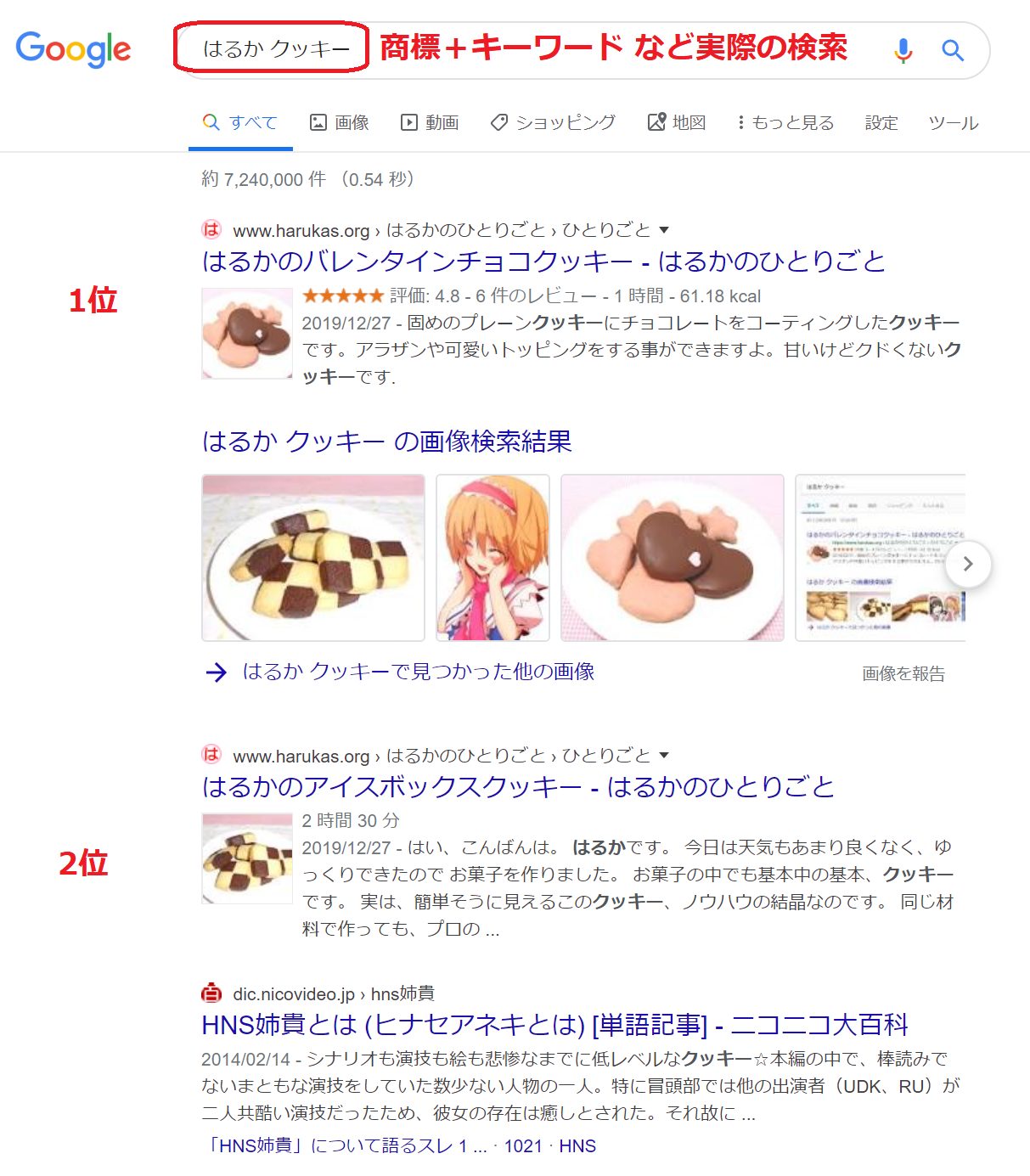
私の記事は、1位、2位の2枠を独占しています。
2020年1月現在のGoogleの仕様は、最大3枠です。(例外あり)
しかし3枠出ることなど殆ど無く、もし出たとしても競合サイトが少ないキーワードで検索している場合が多いです。
アルゴリズムとしては、デフォルトで1位のサイトが3枠取得して、2位以下のコンテンツのキーワード価値が高ければ、記事数が2,1とドンドン減っていきます。
アフィリエイトなどの競合キーワードでは確実に1枠だと考えましょう。
さて、この検索結果を評価してみましょう。
はるかは、私のサイトの商標に非常に近いドメインなので、最初に見せた site:www.harukas.org クッキー で検索した順位のものが、そのまま2枠に入っています。
つまり、1位がバレンタイン、2位がアイスボックスという訳です。
ところで、3位はどこにいったのでしょう?
あまんちゅのクッキーシューが3位でしたが、このページには存在しません。
いえ、次のページもその次のページにも存在しません。
ちょっと、SEOチェキで見てみましょう。
あまんちゅのクッキーシューの記事をSEOチェキで検索
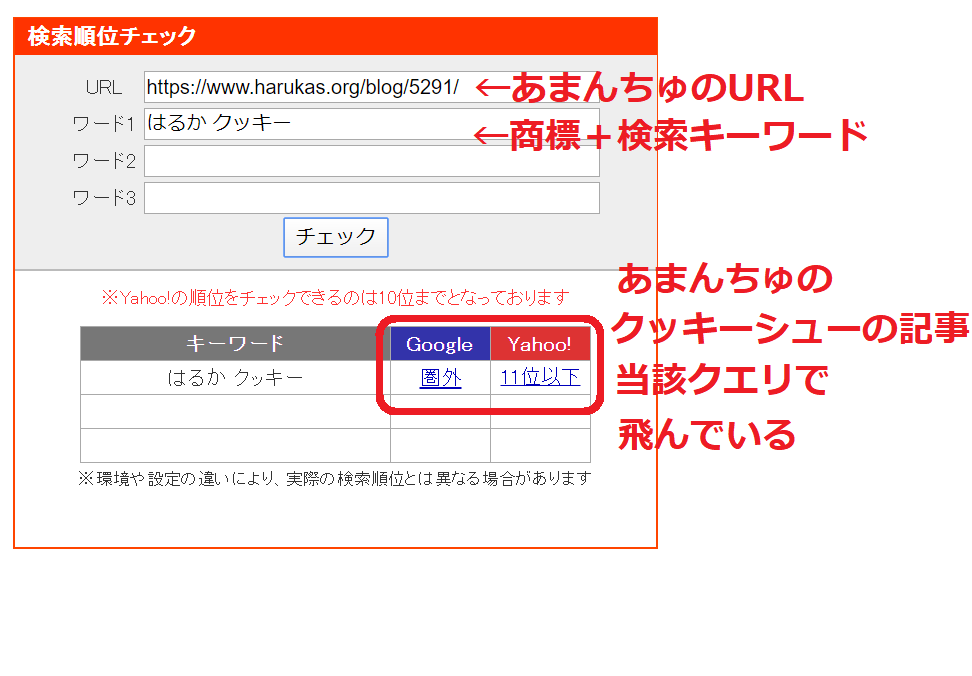
ごらんのように完全に飛んでます。
クッキーシューの記事は、私のファンがいくら「はるか クッキー」で検索しても、検索エンジンで見つける事は不可能なのです。
この例の場合は、枠が2なのでアイスボックスクッキーも表示します。
しかし、アフィリエイトの競合キーワードではあれば枠は1なので、アイスボックスも飛ぶことになります。
つまり重要視するキーワードで記事を書く場合は、ドメイン内の検索結果で1位になる状態が適切だと言えます。
これは極端な例で説明しましたが、似たような記事を量産すると、このように見てもらいたいコンテンツを見てもらえない状況が発生します。
自分のサイト内なのですから、インデックスは順位を含め、自分でコントロールしてください。
すこし補足しておきますが、私は重複コンテンツが悪だと言っている訳ではありません。
むしろ、カテゴリーやタグのキーワードを強くするコンテンツ群で、必要だと言っています。
このあたりの説明は、
顧客心理を追求して売上を伸ばすサイトを作るラダリングとは?に
詳しく書いています。
私が強く言いたいのは、インデックスやコンテンツを、Googleの検索結果に照らし合わせてコントロールする術を身に付けてくださいという事です。
どうですか?Googleの検索順位の仕組みが少しはわかりましたか?
自サイト内の順位が強くないと表示する順番により、検索結果に出ない危険性がある事が理解出来ればOKだと思います。
非HTMLページの重複発生の対策
htmlのページの重複は、canonicalの有無で分類されますが、pdfなど非htmlは、こちらにレポートされます。非htmlなので、linkタグのcanonicalは使用できません。
しかし、HTTPヘッダーを利用して、canonicalを指定する事が可能です。
指定方法は、HTTPのリクエストヘッダ(htmlのheadセクションの事ではない)内に以下を記述します。
Link: <http://www.example.com/downloads/white-paper.pdf> rel=”canonical”
(URLは絶対パスを使用します)
詳細はヘルプを確認してください。
まあCMSのみを使っているサイトではあまり気にすることはないですね。
ただ、pdfはHTMLのように内部を解析しますので、例のようにdownloadsディレクトリ等に、アップロードしている場合は、他のコンテンツとの関連性などを充分に把握しておいてください。
Googleは、pdfを普通のhtmlマークアップのように解析してインデックスしようとします。
法的申し立てによりページが削除されました
Googleは、できる限りWebサイトを公正に扱います。また、不公平と思われる強制的なインデックスの削除は、その情報をWebサイトに公開し、透明性をレポートしています。
この項目は、DMCAというアメリカで著作権を管理している団体に訴訟をおこされた内容で、インデックスを削除する必要があると判断された場合、インデックスが削除されここにレポートされます。
著作権違反など知的財産の侵害をしなかったら、無縁です。
ただ、どのようなとばっちりを受けるか分かりません。
例えば、DMCAに嘘の申請をする第三者がいたとして、自分のサイトのインデックスが削除されるなどです。
こういった場合、サーチコンソールに通知されるので、必ずログインして中身を確認してください。
ページにリダイレクトがあります
リダイレクトを正しく設定していれば、その内容がここにレポートされます。例えば、/無しから/ありのURLにリダイレクトしたり、サイト内でファイルを移動したりした場合、表示されます。
ここで気をつけたいのは、第三者のハッキングなどにより、意味不明なアダルトサイトにリダイレクトされたりする可能性があります。
もし、意図的ではないリダイレクトが発生し、その先がアダルトサイトや偽物通販の場合、ハッキングの可能性が考えられますので、トラブルシューティングに応じて、対応をしてください。
まとめ
いろいろな視点でサーチコンソールにレポートされる問題の解決方法を提示してみました。SEO初心者の方には、必ず役立つコンテンツだと思いますので、じっくりと読んでみてください。
・サーチコンソールの新機能はこれからまだ充実していく
・サーチコンソールに登録してトラブルシューティングできる環境をつくる
・エラーと警告について優先順位を決め対策をおこなう
・URL検査ツールを使いインデックス状態の確認する
・インデックスはコントロールする
ではでは、皆様方のサイトがGoogleフレンドリーになりますように。
































コメント一覧
これはYoastが勝手に仕様変更したためです。
現在不具合がおきるか調査中です。
もし不具合が起きたらYoastは使用しなくなりここで、必ず報告します。
問題がなさそうだと判断した場合も、ここで報告します。
なお、/2/などのサブページをnoindexに指定する方法はとても簡単で、プラグインに頼る必要はありません。
もし、サブページをインデックスする事で不具合が起きたら、指定方法も解説したいと思います。
これが発生すると本来2枠あった場合、2枠目は記事一覧で占有され運営者にとって害にしかなりません。
ただ、そのあとのアルゴリズム改良で修正されていると思います。
もしあっても、まれで、Googleが問題視しているようなので、現在の私の判断は/2/などをnoindexにする必要は無いと考えています。
が表示されて困っていましたが、原因が分かりました。
ちゃんとnoindexが認識されるようにnoindexとrobotのblockを指定していました。
robots.txtでブロックすると検索結果に出ない場合があるので、非表示と勘違いする場合がありますね。
noindexは、絶対命令ですし、robotsによるブロックは通常の運用では全く必要無いと私は思っています。
ソフト404が大量に出てこまっています。何か対策はないでしょうか?
また、以前は正常なコンテンツなのに404相当の低品質な画面にリダイレクトされた場合などでも発生します。
大量発生という事ですが、何かシステム変更をしてませんでしょうか?
リダイレクトのミスなど、エラーの出ているURLを通常のブラウザで確認してどうなるか確認してください。
サーチコンソールで「送信されたurlにnoindexタグが追加されています」となってしまい解決法を探しています。
記事数が45くらいなんですが、エラーが230、除外が390で、変だなと思っていたら、どうやら記事に使った画像がインデックスされていないようで…
画像に名前を「1」とか「2」とかにしてワードプレスに取り込ませていたのが原因なのかな……と自分で思ったのですがが…いかんせん始めたばかりで良く分かりません
大変おこがましいのですが、何かアドバイス頂けますと幸いですm(__)m
こんにちは。
恐らくサイトマップにてインデックスをするように要求しているにも関わらず、そのURLに対してインデックスの必要が無いというnoindexが付与されているのだと思います。
エラーが多いのは、設定などであり得る話です。
まず、画像がインデックスされていないのが問題なのか、何が問題かを教えてください。
画像がインデックスされないページの問題である場合、サイトのURLをここに書くか問い合わせフォームでお願いします。
また、新しいサーチコンソールの「共有」機能で共有いただいてもかまいません。
(管理者機能など与えられず、見るだけの機能でいつでもリンクを削除できます)
画像に1,2などの名前を付けていても、メディア(画像の追加などで出る画面)でタイトルや「代替テキスト」を入れている場合問題ありません。
タイトルや代替テキスト(alt)が無い場合は、問題になります。
Googleに画像を正しくインデックスさせるには?
も合わせてお読みいただけたらと思います。
サーチコンソールについて何点か質問がありコメントしました。
1.インデックスに素早く登録させる一番有効な手段は何でしょうか?
最初は、サイトマップ送信のみで行っていたのですがあまりにも遅かったので、一度全URLをURL検査しインデックス登録されていないものを全て登録しました。それ以降は、ページ新規作成、または、変更するする(変更の場合もインデックス登録でいいのでしょうか?)都度、インデックス登録しているようにしています。これが一番早いような気がするのですか?
2.ワードプレスを使用してページを作成しているのですが(アフィンガー)、オプションでAMPも同時に対応できるようになっています。実際に、通常のページを検査すると、拡張としてAMPも同時に登録されているものもあります。ところが、同じように作成しているのにAMP登録されていないものがあります。むしろされてないほうが多いです。これは、どういった理由でこうなるのでしょうか?また、対処方法(登録)はあるのでしょうか?
3.また、モバイルユーザビリティでないページについては、ページを充実する等の対策をして、インデックス登録を再度行えばいいのでしょうか?
4.ちょっと、サーチコンソールとは話が違うのですが、サイト作成をし始めて6か月がたち、200ページほど作成しました。ただ、サーチコンソールで、1ヵ月30クリック、5200表示回数程度です。これでも、増えては来ているのですが。新規ドメインだと時間がかかると聞いたりしますが、やはり、クリック数がもっと増えるには、ページ数を増やすということが必要なのでしょうか?一応、アフィリエイトで多少利益を得たいという目標もあるのですが、目に見えるものがあまりにもなくて(アフィリエイト収入が少しでもあればいいのですが)、モチベーションの維持が大変です。
何か目標というかモチベーションの維持になるようなことがあれば、教えていただきたいです。
色々思い付きで書いてしまい、申し訳ありません。
ご意見をいただければありがたいです。
以上、よろしくおねがいいたします。
サーチコンソールを利用したFech as Googleを利用するのが最速だと思います。
(新しいサーチコンソールのURL検査ツールを使用してインデックス登録する行為と同様)
ただし、FaGはインデックスに登録できたりクロールが正常に行われるか確認する行為です。
なのでGoogleとしては通常運用を推奨しておらず、通常運用は「サイトマップの送信」がベストプラクティスとなります。
サイトマップを自動生成するような仕組みを導入してください。
2.AMPに登録されていない?
AMPに登録されるか否かは、サーチコンソールのAMPやURL検査で確認してください。
バリデーションが正常に通る様であれば、AMPページとしてインデックスに登録されます。
しかし、AMPがインデックスされたからといって、必ずAMPページが出てくる訳ではありません。
デバイスに応じて、出し分けをしていますし、AMPページを表示するのが適正かどうかはGoogleが判断しています。
よって、出ないからと言って出せるように変更する必要はありません。
・使われているモバイル端末が高速にAMPを表示できるか?(最新のiPhoneなど)
・コンテンツがGoogleの信頼に値する内容になっているのか(価値がないページになっていない)
などを確認するとAMPでの表示可能性が高まります。
3.モバイルユーザビリティでないページの扱い
モバイルユーザビリティでエラーが出ている場合は、当然ですがAMPにも登録されません。
またここでエラーが出ている場合は、検索順位を著しく下げられる可能性がありますので、必ず修正してください。
4.新規作成したページにCTRやPVが上がらない
まず、本当に新規ドメインなのかwaybackなどで確認してください。
新規と思い込んでいて中古であればドメインが自動対策を受けていたりすると、不利になる可能性があります。
ドメインに問題が無いばあいは、コンテンツやページタイトルの問題だと考えられます。
「新規が遅い」という根拠について私は知りませんが、6ヶ月も安定しない事はありません。
やはり、キーワードに応じた順位やコンテンツを見直し、検索者が望んでいるページになっているか、再確認をした方がよいです。
ありがとうございます。
1は、既に自動でサイトマップ送信しています。ただ、新しいサーチコンソールになったあたりから、更新がかなり遅くなっているようで、URL検査でできるならと思っていました。
2は、全てがAMPになるわけではないということでしょうか?それでしたら、理解出来ました。
3は、例えば、現在はモバイルユーザビリティでないけど、ページを充実させてそれを反映させたい場合は、インデックスを再登録必要がなのでしょうか?(FaG等で)
4は、新規であることが確認できました。
サイトの内容にもよると思うのですが、200ページほどのサイトでPV、CTRはどの程度が普通なのでしょうか?
色々答えていただきありがとうございます。
URL検査に連動しているインデックス登録機能は、不具合などを発見した場合の回復手段だと思います。
AMPのインデックスは、すべてのデバイスとKWで表示される訳ではありません。
3の意味がよく分かりませんが、モバイル対応していないという事ですか?
ページを変更した場合、URL検査のインデックス送信機能を使うのは正しい運用だと思います。
あと、200ページの適切なPV/CTRなどは、やはり決まっていないと思います。
サイトやコンテンツに依存するので、検索優先で考えられている場合は、検索者が自分のページで満足しているのか、タグマネージャなどを導入して、スクロールイベントを反映させたりするのも良いかもしれません。
検索アナリティクスのキーワードに対応したページが、あるかないか等も、とても重要だと思います。
3については、ページの変更(内容を充実させたような場合)には、インデックスの再登録をしたほうがいいですか?という質問だったので、再登録したほうがいいということで理解しました。
もう少しキーワードを意識したほうがいいことは、今更ですがなんとなくわかってきました。
今までは、とにかくページ数と量にこだわってきた気がするので。
色々ありがとうございました。
また、質問したいことができたときは、よろしくお願いいたします
いつも的確な回答、解説ありがとうございます。本当に助かります。今回もSerch Console においての曖昧さがすっきりしました。
コメントする